1.如果是想要read到vector中,首先给vector分配足够的大小,之后使用&V[0]即可
2.非read情况,想要将vector<char>转为char*的话
局部使用可以直接
c++ 11后支持
非局部需要把vector拷贝到char*,首先给char*分配内存,然后拷贝
杂记
1.如果是想要read到vector中,首先给vector分配足够的大小,之后使用&V[0]即可
2.非read情况,想要将vector<char>转为char*的话
局部使用可以直接
c++ 11后支持
非局部需要把vector拷贝到char*,首先给char*分配内存,然后拷贝
setjmp/longjmp回退内存
比如在一段代码中,
setjmp相当于将某一个内存打了一个桩
longjmp可以跳转回来
if (setjmp(ptr)) { //第一次使用返回0
}
...
longjmp(ptr, int); //调用longjmp会goto到setjmp语句,并使setjmp返回非0值。
unsigned long hash(unsigned char *str)
{
unsigned long hash = 5381;
int c;
while (c = *str++)
hash = ((hash << 5) + hash) + c; /* hash * 33 + c */
return hash;
}
用这个函数hash几张图片,得到了同样的值,应该是遇到了0,改进一下
把while循环改成for循环就可以了,不过需要知道字符串的长度
unsigned long hash(unsigned char *str, int size)
{
unsigned long hash = 5381;
int i;
for (i = 0; i < size; i++)
{
int c = (int)str[i];
hash = hash * 33 + c;
}
return hash;
}
从输入url,到打开页面发生了什么?
引用知乎上一个比较好玩的答案:
你发现快要过年了,于是想给你的女朋友买一件毛衣,你打开了www.taobao.com。这时你的浏览器首先查询DNS服务器,将www.taobao.com转换成ip地址。不过首先你会发现,你在不同的地区或者不同的网络(电信、联通、移动)的情况下,转换后的ip地址很可能是不一样的,这首先涉及到负载均衡的第一步,通过DNS解析域名时将你的访问分配到不同的入口,同时尽可能保证你所访问的入口是所有入口中可能较快的一个(这和后文的CDN不一样)。
你通过这个入口成功的访问了www.taobao.com的实际的入口ip地址。这时你产生了一个PV,即Page View,页面访问。每日每个网站的总PV量是形容一个网站规模的重要指标。淘宝网全网在平日(非促销期间)的PV大概是16-25亿之间。同时作为一个独立的用户,你这次访问淘宝网的所有页面,均算作一个UV(Unique Visitor用户访问)。最近臭名昭著的12306.cn的日PV量最高峰在10亿左右,而UV量却远小于淘宝网十余倍,这其中的原因我相信大家都会知道。
因为同一时刻访问www.taobao.com的人数过于巨大,所以即便是生成淘宝首页页面的服务器,也不可能仅有一台。仅用于生成www.taobao.com首页的服务器就可能有成百上千台,那么你的一次访问时生成页面给你看的任务便会被分配给其中一台服务器完成。这个过程要保证公正、公平、平均(暨这成百上千台服务器每台负担的用户数要差不多),这一很复杂的过程是由几个系统配合完成,其中最关键的便是LVS,Linux Virtual Server,世界上最流行的负载均衡系统之一,正是由目前在淘宝网供职的章文嵩博士开发的。
经过一系列复杂的逻辑运算和数据处理,用于这次给你看的淘宝网首页的HTML内容便生成成功了。对web前端稍微有点常识的童鞋都应该知道,下一步浏览器会去加载页面中用到的css、js、图片等样式、脚本和资源文件。但是可能相对较少的同学才会知道,你的浏览器在同一个域名下并发加载的资源数量是有限制的,例如ie6-7是两个,ie8是6个,chrome各版本不大一样,一般是4-6个。我刚刚看了一下,我访问淘宝网首页需要加载126个资源,那么如此小的并发连接数自然会加载很久。所以前端开发人员往往会将上述这些资源文件分布在好多个域名下,变相的绕过浏览器的这个限制,同时也为下文的CDN工作做准备。
据不可靠消息,在双十一当天高峰,淘宝的访问流量最巅峰达到871GB/S。这个数字意味着需要178万个4mb带宽的家庭宽带才能负担的起,也完全有能力拖垮一个中小城市的全部互联网带宽。那么显然,这些访问流量不可能集中在一起。并且大家都知道,不同地区不同网络(电信、联通等)之间互访会非常缓慢,但是你却发现很少发现淘宝网访问缓慢。这便是CDN,Content Delivery Network,即内容分发网络的作用。淘宝在全国各地建立了数十上百个CDN节点,利用一些手段保证你访问的(这里主要指js、css、图片等)地方是离你最近的CDN节点,这样便保证了大流量分散已经在各地访问的加速。
这便出现了一个问题,那就是假若一个卖家发布了一个新的宝贝,上传了几张新的宝贝图片,那么淘宝网如何保证全国各地的CDN节点中都会同步的存在这几张图片供用户使用呢?这里边就涉及到了大量的内容分发与同步的相关技术。淘宝开发了分布式文件系统TFS(taobao file system)来处理这类问题。
好了,这时你终于加载完了淘宝首页,那么你习惯性的在首页搜索框中输入了'毛衣'二字并敲回车,这时你又产生了一个PV,然后,淘宝网的主搜索系统便开始为你服务了。它首先对你输入的内容基于一个分词库进行的分词操作。众所周知,英文是以词为单位的,词和词之间是靠空格隔开,而中文是以字为单位,句子中所有的字连起来才能描述一个意思。例如,英文句子I am a student,用中文则为:“我是一个学生”。计算机可以很简单通过空格知道student是一个单词,但是不能很容易明白“学”、“生”两个字合起来才表示一个词。把中文的汉字序列切分成有意义的词,就是中文分词,有些人也称为切词。我是一个学生,分词的结果是:我 是 一个 学生。
进行分词之后,还需要根据你输入的搜索词进行你的购物意图分析。用户进行搜索时常常有如下几类意图:(1)浏览型:没有明确的购物对象和意图,边看边买,用户比较随意和感性。Query例如:”2010年10大香水排行”,”2010年流行毛衣”, “zippo有多少种类?”;(2)查询型:有一定的购物意图,体现在对属性的要求上。Query例如:”适合老人用的手机”,”500元 手表”;(3)对比型:已经缩小了购物意图,具体到了某几个产品。Query例如:”诺基亚E71 E63″,”akg k450 px200″;(4)确定型:已经做了基本决定,重点考察某个对象。Query例如:”诺基亚N97″,”IBM T60″。通过对你的购物意图的分析,主搜索会呈现出完全不同的结果来。
之后的数个步骤后,主搜索系统便根据上述以及更多复杂的条件列出了搜索结果,这一切是由一千多台搜索服务器完成。然后你开始逐一点击浏览搜索出的宝贝。你开始查看宝贝详情页面。经常网购的亲们会发现,当你买过了一个宝贝之后,即便是商家多次修改了宝贝详情页,你仍然能够通过‘已买到的宝贝’查看当时的快照。这是为了防止商家对在商品详情中承诺过的东西赖账不认。那么显然,对于每年数十上百亿比交易的商品详情快照进行保存和快速调用不是一个简单的事情。这其中又涉及到数套系统的共同协作,其中较为重要的是Tair,淘宝自行研发的分布式KV存储方案。
然后无论你是否真正进行了交易,你的这些访问行为便忠实的被系统记录下来,用于后续的业务逻辑和数据分析。这些记录中访问日志记录便是最重要的记录之一,但是前边我们得知,这些访问是分布在各个地区很多不同的服务器上的,并且由于用户众多,这些日志记录都非常庞大,达到TB级别非常正常。那么为了快速及时传输同步这些日志数据,淘宝研发了TimeTunnel,用于进行实时的数据传输,交给后端系统进行计算报表等操作。
你的浏览数据、交易数据以及其它很多很多的数据记录均会被保留下来。使得淘宝存储的历史数据轻而易举的便达到了十数甚至更多个PB(1PB=1024 TB=1048576GB)。如此巨大的数据量经过淘宝系统1:120的极限压缩存储在淘宝的数据仓库中。并且通过一个叫做云梯的,由2000多台服务器组成的超大规模数据系统不断的进行分析和挖掘。
从这些数据中淘宝能够知道小到你是谁,你喜欢什么,你的孩子几岁了,你是否在谈恋爱,喜欢玩魔兽世界的人喜欢什么样的饮料等,大到各行各业的零售情况、各类商品的兴衰消亡等等海量的信息。
上文中绝大多数是一些WEB后端技术,那么前端能做什么呢?
1.减少HTTP请求数
什么是HTTP请求数,一个css-link标签,一个script标签,一个img-src,都需要一次HTTP请求。当然css-link、script很多时候是同步的,且block页面首次渲染,img是异步的。
页面加载中,大多数时间用在HTTP请求上,如果能减少HTTP请求数,就能大幅提高性能。
1)从设计入手,更少的元素显示更丰富的页面内容。
2)css,js文件合并/压缩,很多优秀的工具如grunt可以很方便的完成这件事。
3)CSS Sprites技术,即把所有背景图放到一张图片内,使用CSS技术:background-image,background-position来显示图片的不同部分。
但这个只适用于图片元素紧挨在一起,而且定位比较繁琐,很容易出错,且不能指定手工形状。
2.减少DNS查找次数
3.避免跳转
值得一提的一个现象,如真正的url是 http://xxx.xxx.xx/,而我们输入了http://xxx.xxx.xx,这就会造成一次跳转。
4.可缓存的AJAX
5.延迟加载
确定一下页面哪些内容是页面首次渲染时必须加载的,哪些内容稍微延后加载效果会更好?
6.预加载
预加载是浏览器引擎的一种技术,如页面加载,遇到了js脚本,就需要同步的去解析/执行JS。这时候,开一个线程,遍历一下页面中其他需要下载的元素,去下载它们。
业务预加载:业务的预加载是指在空闲的时候(onload之后),可以使用JS脚本去加载那些尚未显示出来的内容,一般是img,也可以是css和js。
7.减少DOM数量
8.根据域名划分页面内容
9.尽量少的iframe
10.使用CDN
11.为文件头指定Expires和Cache-Contorl
对于静态内容:设置文件头过期时间Expires的值为“Never expire”(永不过期)
对于动态内容:使用恰当的Cache-Control文件头来帮助浏览器进行有条件的请求
12.Gzip
13.使用Etag
14.使用flush
15.使用GET来完成AJAX请求
16.css置于顶部
17.不使用css表达式
18.使用外部js和css
19.js置于页面底部
20.减少JS对DOM的访问
21.优化图像
22.不要缩放图像
http://lehsyh.iteye.com/blog/2111265
Merge request
什么是Merge request,多人开发项目时,发起将一个远程分支merge到另一个分支(一般为主分支)的请求。
merge request步骤:
1.如果开发完了某个模块的功能,需要提交到线上。
2.首先,git fetch --all,仓库代码图拉下来,把线上的代码更新后合并到自己的本地分支上。
3.解决冲突
4.再次合并代码,没有问题后,git push origin 本地分支名。这样就会在远程仓库创建一个remotes/origin/本地分支名 的分支。
5.gitlab上,,进入mergeRequest页面,选择newMergeRequest(右上角绿色按钮)。
6.选择要merge的source分支,CONTINUE。
7.填写描述,添加reviwer(重要)。
8.等待结果,如果有冲突,需要从头再来。
Reset
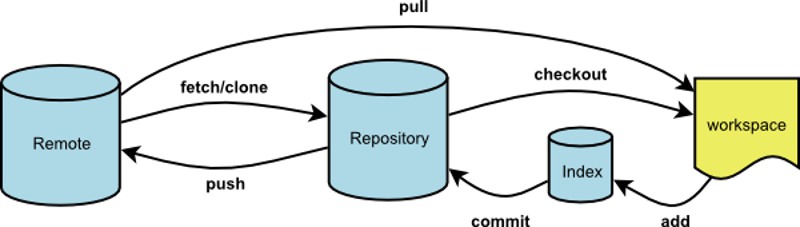
git reset 撤销命令
reset有三种模式
git reset --soft HEAD 本地文件不变,撤销掉commit,不撤销index
git reset --hard HEAD 本地文件改为HEAD,所有commit/index都修改掉
git reset HEAD 本地文件不变,撤销掉commit/index
如果只想恢复某一个文件,只需要
git checkout filename
恢复所有文件到当前HEAD
git checkout .
调用glclear接口,发现它耗时比较长,翻了翻stackoverflow。
Measuring the elapsed time of an OpenGL API call is mostly meaningless.
研究OpenGL接口的耗时是无意义的。
The key aspect to understand is that OpenGL is an API to pass work to a GPU.
The easiest mental model (which largely corresponds to reality) is that when you make OpenGL API calls, you queue up work that will later be submitted to the GPU. For example, if you make a glDraw*() call, picture the call building a work item that gets queued up, and at some point later will be submitted to the GPU for execution.
In other words, the API is highly asynchronous. The work you request by making API calls is not completed by the time the call returns. In most cases, it's not even submitted to the GPU for execution yet. It is only queued up, and will be submitted at some point later, mostly outside your control.
A consequence of this general approach is that the time you measure to make a glClear() call has pretty much nothing to do with how long it takes to clear the framebuffer.
Now that we established how the OpenGL API is asynchronous, the next concept to understand is that a certain level of synchronization is necessary.
Let's look at a workload where the overall throughput is limited by the GPU (either by GPU performance, or because the frame rate is capped by the display refresh). If we kept the whole system entirely asynchronous, and the CPU can produce GPU commands faster than the GPU can process them, we would be queuing up a gradually increasing amount of work. This is undesirable for a couple of reasons:
To avoid this, drivers use throttling mechanisms to prevent the CPU from getting too far ahead. The details of how exactly this is handled can be fairly complex. But as a simple model, it might be something like blocking the CPU when it gets more than 1-2 frames ahead of what the GPU has finished rendering. Ideally, you always want some work queued up so that the GPU never goes idle for graphics limited apps, but you want to keep the amount of queued up work as small as possible to minimize memory usage and latency.
With all this background information explained, your measurements should be much less surprising. By far the most likely scenario is that your glClear() call triggers a synchronization, and the time you measure is the time it takes the GPU to catch up sufficiently, until it makes sense to submit more work.
Note that this does not mean that all the previously submitted work needs to complete. Let's look at a sequence that is somewhat hypothetical, but realistic enough to illustrate what can happen:
glClear() call that forms the start of rendering frame n.n - 3 is on the display, and the GPU is busy processing rendering commands for frame n - 2.glClear() call until the GPU finished the rendering commands for frame n - 2.n - 2 is shown on the display, which means waiting for the next beam sync.n - 2 is on the display, the buffer that previously contained frame n - 3 is not used anymore. It is now ready to be used for frame n, which means that the glClear()command for frame n can now be submitted.Note that while your glClear() call did all kinds of waiting in this scenario, which you measure as part of the elapsed time spent in the API call, none of this time was used for actually clearing the framebuffer for your frame. You were probably just sitting on some kind of semaphore (or similar synchronization mechanism), waiting for the GPU to complete previously submitted work.
Considering that your measurement is not directly helpful after all, what can you learn from it? Unfortunately not a whole lot.
If you do observe that your frame rate does not meet your target, e.g. because you observe stuttering, or even better because you measure the framerate over a certain time period, the only thing you know for sure is that your rendering is too slow. Going into the details of performance analysis is a topic that is much too big for this format. Just to give you a rough overview of steps you could take:
OpenGL是GPU的API
API call是以eventloop的形式工作
但需要一定的同步工作,任务数量太多,延迟会变大,开发者又需要尽快响应用户,GPU需要跟CPU保持一定过得同步。简单的来说,如果CPU发出的绘制指令超出GPU太多(1-2帧),GPU会锁住CPU。
在这个背景下,就可以解释为什么glClear耗时了,因为它触发了一次同步。
已3个缓冲区为例,n-3在绘制,n-2在合成,The driver decides that you really should not be getting more than 2 frames ahead。glClear就会block住,直到GPU工作完。
GPU工作渲染完n-2,glClear就会提交n。
最终结论,绘制太慢导致的。
可以看看CPU消耗,看看是不是CPU被锁住了。
adb install 一个apk错误:
INSTALL_FAILED_ALREADY_EXISTS
应用已存在,使用 adb install -r xx.apk 即重新安装
INSTALL_PARSE_FAILED_INCONSISTENT_CERTIFICATES
签名冲突,说明系统存在这个应用,且签名有冲突,先执行 adb uninstall xx.apk
但还是提示这个错误
如何彻底卸载掉一个apk?
去/data/system/packages.xml中,把这个包相关的行全部删掉
INSTALL_FAILED_UID_CHANGED
应用删除不干净,还有残留文件,去
/data/app(apk file), /system/app/(apk file), /data/data/(data file)几个目录下,把应用相关数据删掉。
重启
安装成功。
看到一篇很好的文章,浏览器的工作原理,http://www.html5rocks.com/zh/tutorials/internals/howbrowserswork/
看一遍,把要点梳理一下。
1.浏览器的结构
1)UI 主界面、地址栏、前进后退等
2)Browser engine,adapter层。
3)render engine,如果adapter层发来html的请求,render会解析html和css,并将结果最终渲染到屏幕上。
4)network,底层网络模块,与平台无关,负责所有网络接口。
5)JavaScript解释器,负责解析和执行JS
6)UI后端,绘制基本的窗口小控件,和平台无关,在底层使用操作系统的绘制方法。
7)数据存储,如cookie和indexdb等
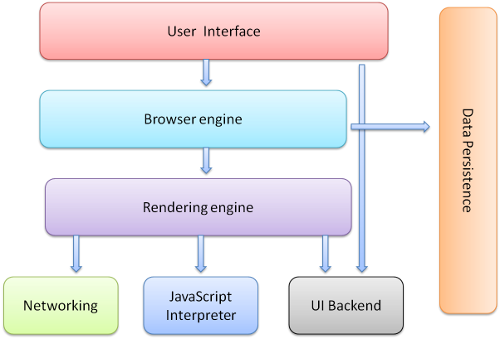
Render Engine,渲染引擎
渲染引擎是web的核心,因为web中一般不做复杂的计算等操作。页面需要及时响应用户操作,流畅的渲染。那么来看一下渲染的基本流程

1.解析HTML,生成DOM-TREE,解析CSS,生成CSSOM,合成RenderTree,就是包含一堆矩形的树,树结构代表了显示顺序。
2.layout,计算位置
3.paint
下图是webkit的渲染过程
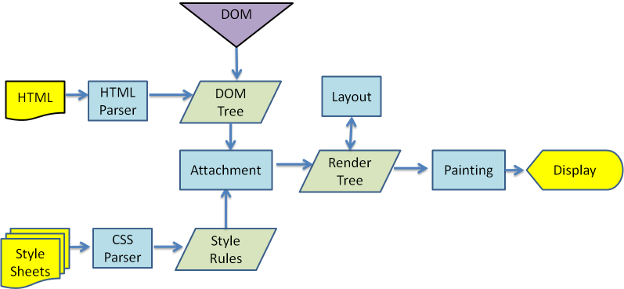
解析过程
上面的流程中,HTML Parser CSS Parser都涉及到了一个解析的过程,什么是解析?
解析就是把文档转化成代码能理解的结构,生成结果被称为解析树或语法树。
解析基于确定的语法规则,即与上下文无关的语法。
解析可以分为两个过程:词法分析和语法分析。
解析把两个过程交给两个组件,词法分析器和解析器。
词法分析器负责把输入内容分成一个个标记。
解析器负责把标记构建成解析树。解析器的解析是一个迭代过程,即向词法分析器请求一个新标记,如果匹配语法规则,则把对应该标记的节点添加到解析树中,如果不匹配,则把这个标记缓存,继续请求标记,直到找到一个匹配的语法规则。
解析树往往还不是最终产品,这个时候需要使用编译器把解析树转成机器代码。
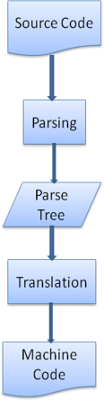
一般的解析可以去看龙书,Html语言不适用于常规解析器,因为HTML不是一种上下文无关的语言,这源于HTML有一定的容错能力。CSS和JavaScript可以。
HTML有自定义的解析器,采用DTD格式定义。
解析算法分为两个步骤,标记化和构建树:
标记化算法使用状态机驱动,该算法比较复杂,通过一个例子叙述:
1.初始状态为 数据状态,
2.遇到<时,更改为标记打开状态,
3.之后读取一个a-z字符,进入标记名状态
4.直到遇到>,进入数据状态
5.数据状态下去读Hello world,直到<,进入标记打开状态
6.标记打开状态下遇到/号,创建 end tag token并进入标记名状态
7.读取a-z字符直到>,回到数据状态。
解析器创建时,会创建Document对象。在解析器工作的时候,已Document为根节点的DOM树不断更新,解析器生成的元素不仅仅会加入DOM树,还会放到堆栈中去,堆栈用来纠正嵌套错误和未关闭的标记。
树构建过程
树构建阶段的输入是一个来自标记化阶段的标记序列。第一个模式是“initial mode”。接收 HTML 标记后转为“before html”模式,并在这个模式下重新处理此标记。这样会创建一个 HTMLHtmlElement 元素,并将其附加到 Document 根对象上。
然后状态将改为“before head”。此时我们接收“body”标记。即使我们的示例中没有“head”标记,系统也会隐式创建一个 HTMLHeadElement,并将其添加到树中。
现在我们进入了“in head”模式,然后转入“after head”模式。系统对 body 标记进行重新处理,创建并插入 HTMLBodyElement,同时模式转变为“in body”。
现在,接收由“Hello world”字符串生成的一系列字符标记。接收第一个字符时会创建并插入“Text”节点,而其他字符也将附加到该节点。
接收 body 结束标记会触发“after body”模式。现在我们将接收 HTML 结束标记,然后进入“after after body”模式。接收到文件结束标记后,解析过程就此结束。
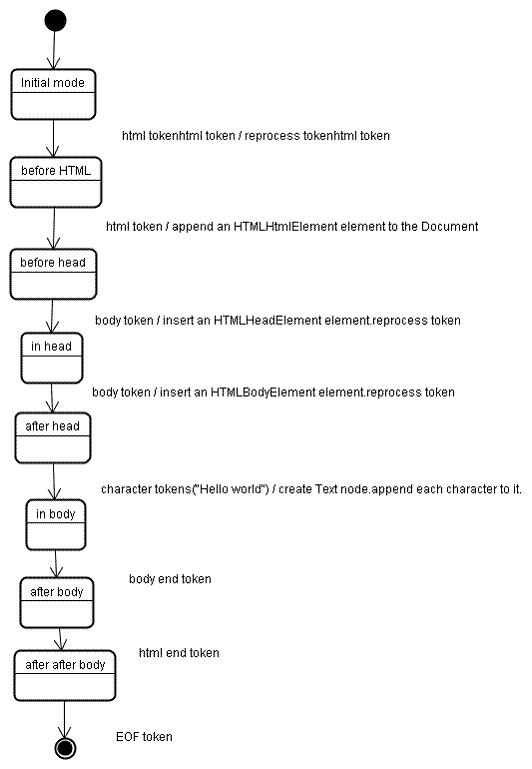
树构建过程
解析过程结束后,浏览器将文档注为交互状态,开始加载 defferd模式下的脚本。然后文档状态成为完成,随之触发加载事件。
容错
浏览器底层有大量的代码来对诸如 无效tag,结束符错误等容错。
来看看webkit的容错说明
解析器对标记化输入内容进行解析,以构建文档树。如果文档的格式正确,就直接进行解析。
遗憾的是,我们不得不处理很多格式错误的 HTML 文档,所以解析器必须具备一定的容错性。
我们至少要能够处理以下错误情况:
CSS解析是遵循一般的解析规则的,这里不赘述。
脚本和文档处理的顺序
当遇到一个script标签时,会立即停止文档的解析,进行js解析。
如果script标签带有defer标记,则会在文档解析完成后再解析。
h5增加了一个标记,将script标记为异步,则会开线程去解析它。
预解析
这是一项优化。在执行脚本的时候,其他线程回去解析剩下的文档部分,找出并加载需要下载的网络资源。预解析器不会动DOM树,只是寻找需要下载的资源。
样式表
理论上CSS和HTML不是一个解析器,但有些JS会请求CSS,所以浏览器在解析CSS的时候会禁止有交互的脚本。
Render-Tree
在DOM-Tree构建的时候,同时也在生成一个Render-Tree。Render-Tree是DOM-Tree的子集,它不包含那些display:none的元素,以及head等。
一般情况下DOM-Tree和Render-Tree的位置是对应的,但不包括absolute和float等非文档流内容,它们位于其他位置,原位置放一个占位符。
样式计算
样式计算是个复杂而庞大的工程,如 匹配规则为 div div div div,这样的匹配会很耗时,而且找了很久可能找到一个三层的。
浏览器为了样式计算进行了很多工作
特异性这里详细记一下
某个样式的属性声明可能会出现在多个样式表中,同一个样式表中也可能出现多次,那么他们的重要性为(优先级从低到高):
1.浏览器声明
2.用户普通声明
3.作者普通声明
4.作者重要声明
5.用户重要声明
同样顺序的声明,按照特异性排序
特异性是 a-b-c-d
a:声明来自style,标记为1,否则为0
b:选择器中ID属性的个数
c:选择器中class属性和伪类的个数
d:选择器中元素名称和伪类的个数
这里不详细叙述。
布局-layout
layout是一个比较重的环节,不仅仅是layout消耗时间,而是layout后一定会引发paint。
HTML采用流式布局,意味着可以遍历一次就计算出来所有位置,从左到右,从上到下。有些特殊的如 表格需要多次遍历。
每一个节点都有一个layout/reflow方法,是一个递归过程。
Dirty位系统
为了避免细小改动都要进程整体布局,浏览器采用了Dirty位的设计。如果某个节点发生了改变,则将其与子代标注为dirty。还有一种标记,children are dirty,表示节点至少有一个子代需要重新布局。
布局分全局和增量两种
全局指必须重新布局,增量是只布局dirty节点(可能还需要布局其他元素)。全局布局是同步的,增量布局一般是异步的。
布局优化,如果只是位置改变或者缩放等,可以直接从缓存取原大小。某些子树修改,不必全局重新layout,如input,不会每输入一次就来一次全局更新。
Paint
paint的内容比较少,只是调用节点的paint方法。paint也有全局绘制和增量绘制两种。
优化
webkit在paint时会缓存之前的矩形,只绘制新旧矩形的差异部分。而当元素有了变化,浏览器会尽量做最小的改动。
线程
Render engin是单线程。
loop
主线程是一个loop,事件循环。
CSS模型
可视化模型,指画布
框模型,由框大小,padding,margin,border组成,display指定
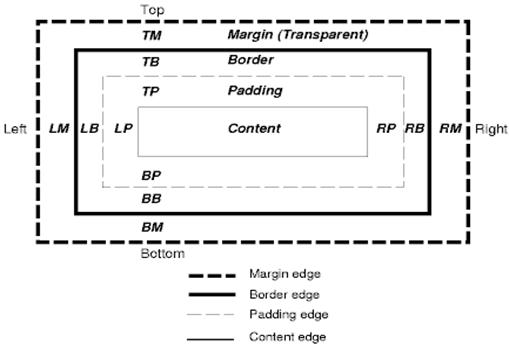
position
普通 浮动 绝对
display:block 普通的矩形,拥有自己的区域
display:inline 没有自己的区域,位于容器block中
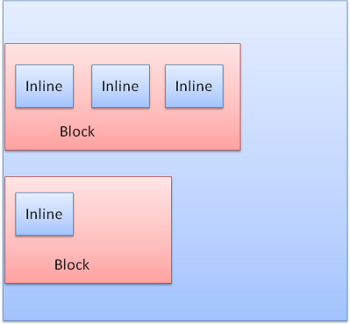
block是垂直的,inline是水平的
分层
z-index表示了框的第三个维度
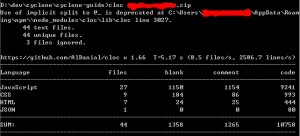
cloc是一个很方便的代码行数统计工具,官网 http://cloc.sourceforge.net/;
安装
我这里使用的npm安装(需要安装node),npm install -g cloc安装好后,命令行敲cloc会给出使用指令,这里不一一详述,只给一个最简单的使用方法。
把要统计的文件打成zip包,然后 cloc xx.zip,就可以了。
Node.js底层有三个重要部分
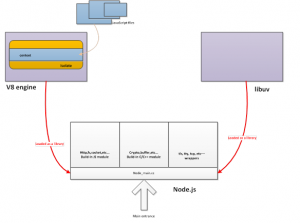
libuv 建立事件循环
v8 引擎以及JS/C++对象转换
node提供的模块 fs os net process等
libuv是一个神器,事件循环,适合状态机驱动的架构,单独学习。
v8的请看google的官方API文档。
今天主要看一下node的模块。
1.js2c.py
node内置了很多js文件,包括主程序 src/node.js和模块文件lib/*.js。js2py是把每一个js文件都生成一个源码数组,存放在node_natives.h中。
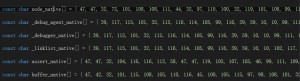
node_native.h中,每个js文件对应一个数组,源码以const char数组的形式存放。
node_native在映射完毕后,变成了这样一个数组。
2.node_javascript.cc
node_javascript.cc include了node_native.h,并提供两个方法:
MainSource(),只有一句
return OneByteString(env->isolate(), node_native, sizeof(node_native) - 1);
返回node_native映射的js文件,即node.js,转换成了一个v8::handle类型。
图:node_native,node.js映射后的数组。
DefineJavaScript(env, target)
将所有js文件映射到Object型的target(不包括node.js)
target->Set(name, source)
综上,node_javascript.cc做了两件事,返回node.js的v8::handle,
返回lib/*.js的Object,{name: v8::handle, name: v8::handle .....}
现在所有js文件都被转换成了v8::handle。
3.node.cc
node.cc是nodejs的main文件,这里我们先认识一个node世界中的风云人物,process。
在node.cc的CreateEnvironment函数中,process出生了,下面我们从源码看看process是个什么?被赋予了哪些属性?
从上面这段代码可以看出process的原始属性,FunctionTemplate,很明显,是js里的一个function,function的name为process。
现在JS世界中已经多了一个叫process的function,那么它是在哪里成长的呢?
在node.cc的LoadEnvironment函数中,
运行MainSource
拿到了node.js的返回f_value,即node.js函数,入参为process的闭包函数,
(function(process) {})
验明正身,执行node.js闭包函数,最后一句做JS的同学看着肯定很眼熟,这不就是
(function(process){}).call(global, process)
4.fs.js
这里通过一个fs模块的创建与加载,来展示process呼风唤雨的能力。
首先规规矩矩的加载了几个模块,然后突然出现了binding
Binding在node.cc中实现
主要逻辑为,查看cache中是否有这个模块,如果没有就新建一个。
新建模块:如果存在builtin,则使用nm_context_register_func方法注册到cache中,如果是常量,cache中注册常量,如果是natives,绑定所有lib/*.js。
在fs中,process.binding找到了fs,是一个builtin模块。这个模块在node_file.cc中实现,最后通过NODE_MODULE_CONTEXT_AWARE_BUILTIN注册到builtin。
Binding函数完成了js上调用C++模块。
5.node.js
node.js中通过一个NativeModules来管理js模块,
process.binding('natives'),将所有内置js模块绑定到_source上。
之后可以通过require方法来拿到这些模块。
先检查cache,如果cache没有,就在process.moduleLoadList中增加一个,然后缓存,执行.
缓存就是把模块放到_cache中,compile函数
通过C++模块contextify运行了这段js。