最长递增子序列的解法,可以转化为 求最长公共子序列,也就是生成从目标序列从小到大排序之后的新序列,然后计算原始序列与新序列的 最长公共子序列。但是遇到重复数字的时候,会出现问题。也就是这个解法只能解决无重复数字的最长递增子序列。
另外需要注意的就是 最长公共子串(Longest Common Substring)与 最长公共子序列(Longest Common Subsequence)的区别: 子串要求在原字符串中是连续的,而子序列则只需保持相对顺序,并不要求连续。
整个的求解过程其实很好理解:
- 假定要计算的序列为 K = {K1,K2,K3,……,Kn,Kn+1,……,Km}
- 初始化计数数组 N = {N1,N2,N3,……,Nn,Nn+1,……,Nm} ,(计数数组跟序列的长度相同,Kn 的最长递增子序列长度计数对应于 Nn)用来记录最长递增子序列的长度,每个项的初始化值都设置为 1 (即使最小的项,项本身也算一个长度,因此最小的长度是 1)
- 必须从头部(K1)开始遍历
- 当计算 Kn 结尾的最长递增子序列的时候,只要遍历序列 K 的前 [0 ~ n-1] 个项,找到数值 小于(或者小于等于) Kn (必须遍历,Kn 之前的最长递增子序列不一定是 Kn-1 对应的 Nn-1 ),并且在计数数组 N 中对应的计数最大的项 Ni ,然后 Nn = Ni + 1 。
本方法的时间复杂度是 O(n2)
例子:
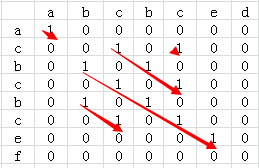
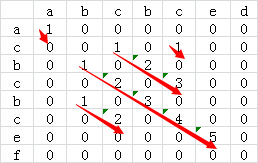
设数组 K = { 2, 5, 1, 5, 4, 5 } 那么求最长递增子序列的代码如下:
第二个测试用例的数据如下:
涉及到的面试题目如下类型:
梅花桩问题
合唱队问题
合唱队问题
合唱队问题其实是 求最长递增子序列 与 最长递减子序列 的 和 最大。
最长递减子序列的求法其实就是把原始序列反序,然后 求最长递增子序列 然后把最后的结果反序即可。
代码如下:
解法介绍