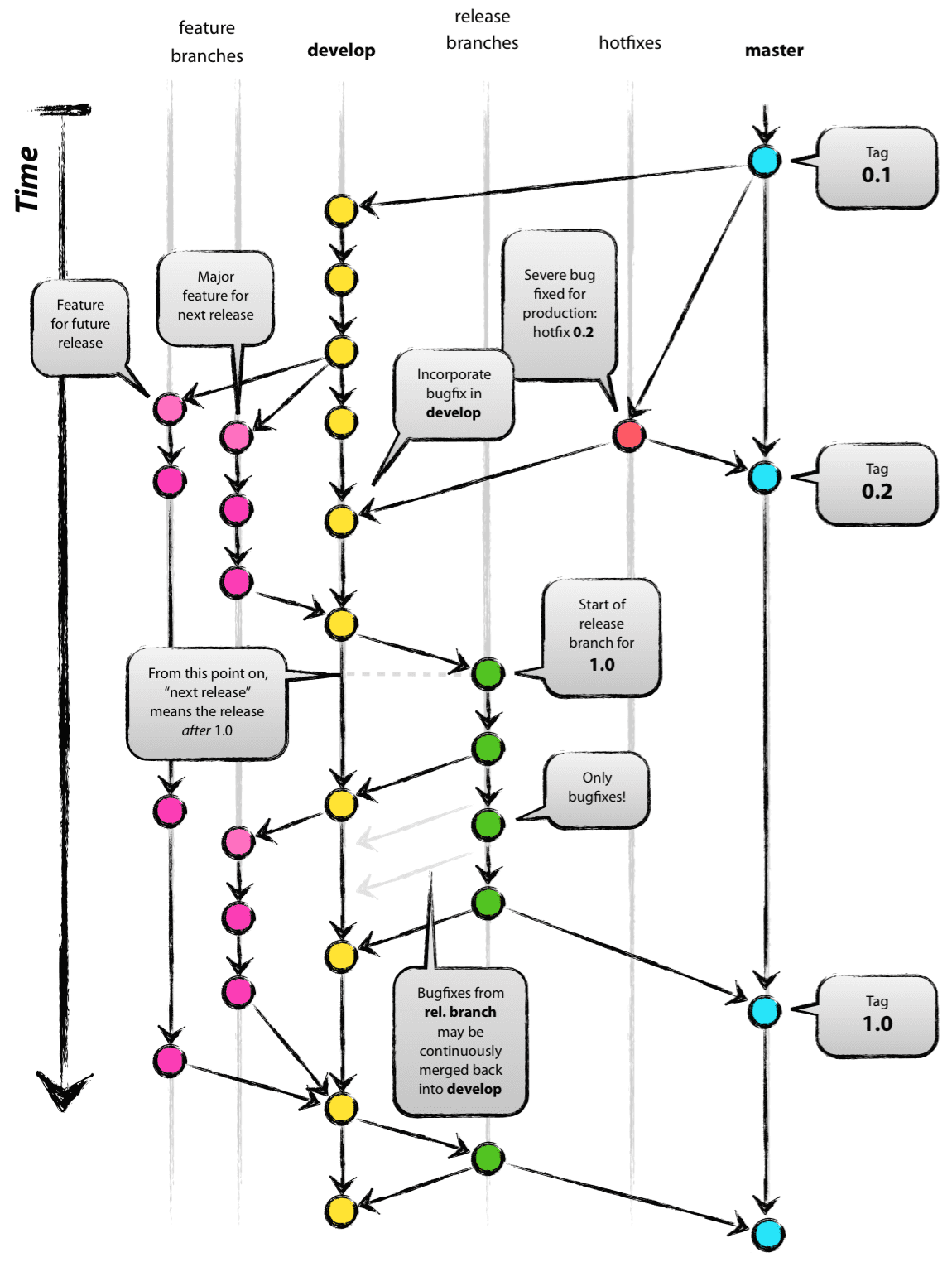
前置条件
- Windows 11 专业版 24H2
- podman desktop 1.17.2 x64
- Gitea 1.23.6
动手实践
Windows 的本质是是安装一个 Linux 虚拟机,然后在虚拟机中安装 Gitea ,所以会出现后面需要进行端口数据转发。
后续如果想修改配置文件,那么需要通过 podman machine ssh 进入容器进行修改。
另外虚拟机整个被默认WSL2 挂载到 \\wsl.localhost\ 目录下,可以直接在 Windows 系统下访问,但是修改的时候可能会没有权限,还是需要通过命令行修改。
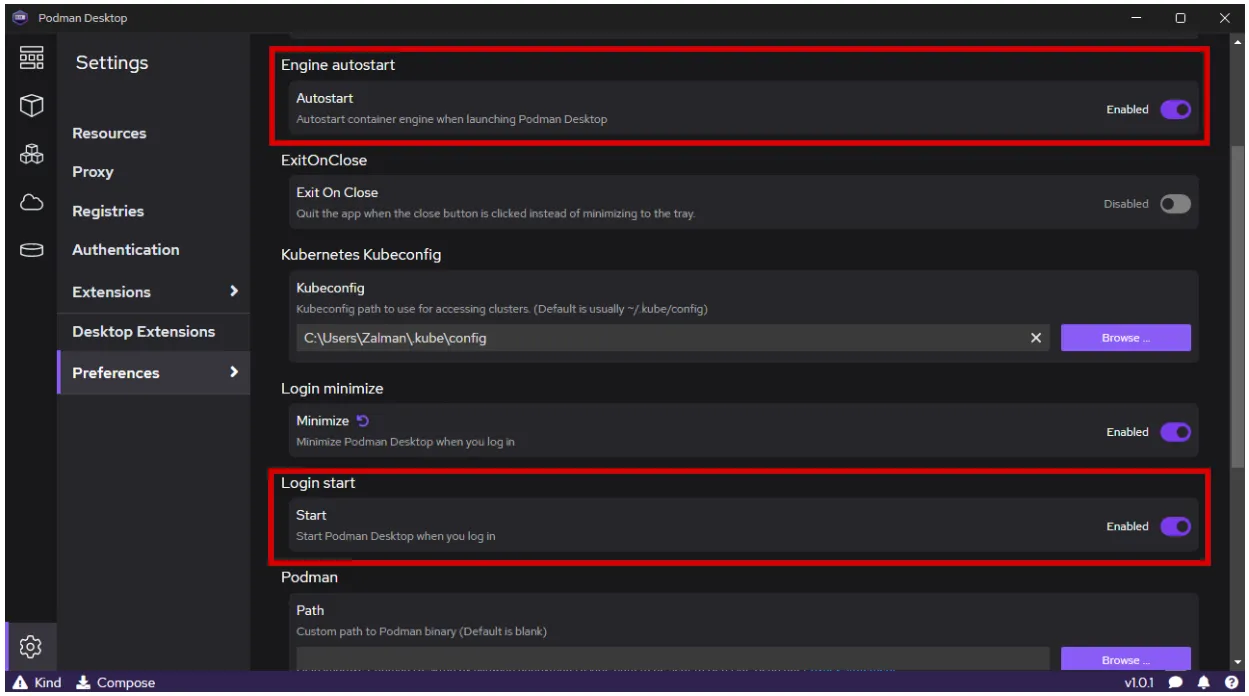
如果 Podman Desktop 没有开机自启动,确认如下如下配置是否已经勾选:
注意:如果对大型项目进行镜像部署,比如 chromium 。登录之前可以正常使用,登录特别慢,注意观察 Podman 的 Logs 项,如果观察到如下内容,特别是 [Slow SQL Query] 相关的日志输出:
上述的输出非常的不合理,简单的 SQL 语句执行耗时高达 26分钟,这个结果是非常不合理的。SQLite 的性能不可能这么差劲。
导出数据库文件,通过 SQLiteStudio 执行相同的 SQL 语句,在 0.1 毫秒执行结束。
并且 Docker 多次重启之后,高概率发生文件损坏。另一个常见现象是处理器占用长时间处于高位,某几个核心长时间满负荷,但是 DUMP 堆栈调用又一切正常,看不到用户态的高占用函数。
这个原因是由于 Windows 和 Linux 的跨系统文件兼容性问题无法得到很好的解决,WSL 2 下访问 Windows 文件性能会非常差。
具体解释参考 [wsl2] filesystem performance is much slower than wsl1 in /mnt #4197 。

解决这个问题的方法就是不要进行映射,直接在存储在虚拟机的磁盘里。
同时,建议内存不低于 32GB ,大型项目,如果内存不足的话,也可能诱发此类问题。
参考链接
- 【windows】查看和开放特定的端口
- 使用命令行管理 Windows 防火墙
- Accessing network applications with WSL
- Netsh interface portproxy commands
- GitLab的替代者-轻量级Gitea安装与配置
- 记录一次 Windows 端的 podman 启动的容器应用外部引用无法访问的问题处理
- Podman: Networking in WSL
- windows上使用netsh映射端口至Hyper-v虚拟机
- Podman container on Windows cannot access host by ip or dns. Linux and Mac OS do not have this issue.#13966
- windows下安装podman ,无法通过本机ipv4地址访问容器,但是127.0.0.1可以访问
- Podman for Windows
- How to Autostart Podman Containers on Windows ?
- Slow browsing on http2 enabled reverse proxy (apache2), long-polling /user/events blocks other requests #19265
- Very slow to load pages
- gitea Reverse Proxies
- Apache Module mod_proxy
- LANDING_PAGE=login leads to endless redirects if you're logged in #28231
- Using Apache HTTPD with a sub-path as a reverse proxy
- Option to show login page instead of home page #9597
- WSL 中的高级设置配置
- 只给对象实现功能所需的最小权限和可见性
- Windows 10 Docker 基于 WSL 2 时读写性能的坑
- WSL2文件系统处理速度较慢
- [wsl2] filesystem performance is much slower than wsl1 in /mnt #4197
- 在 Windows 上安装 Podman 桌面和 Podman
- Hyper-V: How to Enable It and Fix Its Assembly Not Found Error
- 已解决 WSL / WSL2 请启用虚拟机平台 Windows 功能并确保在 BIOS 中启用虚拟化问题
- 如何在Windows 10中彻底卸载并移除Ubuntu WSL子系统及其配置文件
- Podman desktop setup - WSL import of guest OS failed: exit status 0xffffffff #8233
- Permission denied is returned when trying to access some host folders mounted in Hyper-V machines #25686
- 如何在Win11下安装linux子系统(WSL1),并配置anaconda+pytorch深度学习环境的完整教程(30系列显卡包括RTX3090也适用)
- 全网最全Win10/11系统下WSL2+Ubuntu20.04的全流程安装指南(两种支持安装至 D 盘方式)
- WSL 使用中遇到的问题及解决方案 #2 - DrvFs 文件系统权限问题
- WSL 使用中遇到的问题及解决方案 #3 - SSH 密钥权限问题
- 在 WSL 2 中装载 Linux 磁盘
- windows wsl挂载本地vhdx、扩展vdhx磁盘与wsl常见问题
- Windows下Podman Desktop容器目录迁移至其他硬盘的详细步骤