JAVA中的内存泄漏
JAVA编程中的内存泄漏,从泄漏的内存位置角度可以分为两种:JVM中Java Heap的内存泄漏;JVM内存中native memory的内存泄漏。
Java Heap的内存泄漏
Java对象存储在JVM进程空间中的Java Heap中,Java Heap可以在JVM运行过程中动态变化。如果Java对象越来越多,占据Java Heap的空间也越来越大,JVM会在运行时扩充Java Heap的容量。如果Java Heap容量扩充到上限,并且在GC后仍然没有足够空间分配新的Java对象,便会抛出out of memory异常,导致JVM进程崩溃。
Java Heap中out of memory异常的出现有两种原因——①程序过于庞大,致使过多Java对象的同时存在;②程序编写的错误导致Java Heap内存泄漏。
多种原因可能导致Java Heap内存泄漏。JNI编程错误也可能导致Java Heap的内存泄漏。
JVM中native memory的内存泄漏
从操作系统角度看,JVM在运行时和其它进程没有本质区别。在系统级别上,它们具有同样的调度机制,同样的内存分配方式,同样的内存格局。
JVM进程空间中,Java Heap以外的内存空间称为JVM的native memory。进程的很多资源都是存储在JVM的native memory中,例如载入的代码映像,线程的堆栈,线程的管理控制块,JVM的静态数据、全局数据等等。也包括JNI程序中native code分配到的资源。
在JVM运行中,多数进程资源从native memory中动态分配。当越来越多的资源在native memory中分配,占据越来越多native memory空间并且达到native memory上限时,JVM会抛出异常,使JVM进程异常退出。而此时Java Heap往往还没有达到上限。
多种原因可能导致JVM的native memory内存泄漏。例如JVM在运行中过多的线程被创建,并且在同时运行。JVM为线程分配的资源就可能耗尽native memory的容量。
JNI编程错误也可能导致native memory的内存泄漏。对这个话题的讨论是本文的重点。
JNI编程中明显的内存泄漏
JNI编程实现了native code和Java程序的交互,因此JNI代码编程既遵循 native code编程语言的编程规则,同时也遵守JNI编程的文档规范。在内存管理方面,native code编程语言本身的内存管理机制依然要遵循,同时也要考虑JNI编程的内存管理。
本章简单概括JNI编程中显而易见的内存泄漏。从native code编程语言自身的内存管理,和JNI规范附加的内存管理两方面进行阐述。
Native Code本身的内存泄漏
JNI编程首先是一门具体的编程语言,或者C语言,或者C++,或者汇编,或者其它native的编程语言。每门编程语言环境都实现了自身的内存管理机制。因此,JNI程序开发者要遵循native语言本身的内存管理机制,避免造成内存泄漏。以C语言为例,当用malloc()在进程堆中动态分配内存时,JNI程序在使用完后,应当调用free()将内存释放。总之,所有在native语言编程中应当注意的内存泄漏规则,在JNI编程中依然适应。
Native语言本身引入的内存泄漏会造成native memory的内存,严重情况下会造成native memory的out of memory。
Global Reference引入的内存泄漏
JNI编程还要同时遵循JNI的规范标准,JVM附加了JNI编程特有的内存管理机制。
JNI中的Local Reference只在native method执行时存在,当native method执行完后自动失效。这种自动失效,使得对Local Reference的使用相对简单,native method执行完后,它们所引用的Java对象的reference count会相应减1。不会造成Java Heap中Java对象的内存泄漏。
而Global Reference对Java对象的引用一直有效,因此它们引用的Java对象会一直存在Java Heap中。程序员在使用Global Reference时,需要仔细维护对Global Reference的使用。如果一定要使用Global Reference,务必确保在不用的时候删除。就像在C语言中,调用malloc()动态分配一块内存之后,调用free()释放一样。否则,Global Reference引用的Java对象将永远停留在Java Heap中,造成Java Heap的内存泄漏。
JNI编程中潜在的内存泄漏——对LocalReference的深入理解
Local Reference在native method执行完成后,会自动被释放,似乎不会造成任何的内存泄漏。但这是错误的。对Local Reference的理解不够,会造成潜在的内存泄漏。
本章重点阐述Local Reference使用不当可能引发的内存泄漏。引入两个错误实例,也是JNI程序员容易忽视的错误;在此基础上介绍Local Reference表,对比native method中的局部变量和JNI Local Reference的不同,使读者深入理解JNI Local Reference的实质;最后为JNI程序员提出应该如何正确合理使用JNI Local Reference,以避免内存泄漏。
错误实例 1
在某些情况下,我们可能需要在native method里面创建大量的JNI Local Reference。这样可能导致 native memory的内存泄漏,如果在native method返回之前native memory已经被用光,就会导致native memory的out of memory。
在代码清单 1 里,我们循环执行count次,JNI functionNewStringUTF()在每次循环中从Java Heap中创建一个String对象,str是Java Heap传给JNI native method的Local Reference,每次循环中新创建的String对象覆盖上次循环中str的内容。str似乎一直在引用到一个String对象。整个运行过程中,我们看似只创建一个Local Reference。
执行代码清单1的程序,第一部分为Java代码,nativeMethod(int i)中,输入参数设定循环的次数。第二部分为JNI代码,用C语言实现了nativeMethod(int i)。
清单 1. Local Reference引发内存泄漏
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
Java 代码部分 class TestLocalReference { private native void nativeMethod(int i); public static void main(String args[]) { TestLocalReference c = new TestLocalReference(); //call the jni native method c.nativeMethod(1000000); } static { //load the jni library System.loadLibrary("StaticMethodCall"); } } JNI代码,nativeMethod(int i)的C语言实现 #include<stdio.h> #include<jni.h> #include"TestLocalReference.h" JNIEXPORT void JNICALL Java_TestLocalReference_nativeMethod (JNIEnv * env, jobject obj, jint count) { jint i = 0; jstring str; for(; i<count; i++) str = (*env)->NewStringUTF(env, "0"); } 运行结果 JVMCI161: FATAL ERROR in native method: Out of memory when expanding local ref table beyond capacity at TestLocalReference.nativeMethod(Native Method) at TestLocalReference.main(TestLocalReference.java:9) |
运行结果证明,JVM运行异常终止,原因是创建了过多的Local Reference,从而导致out of memory。实际上,nativeMethod在运行中创建了越来越多的JNI Local Reference,而不是看似的始终只有一个。过多的Local Reference,导致了JNI内部的JNI Local Reference表内存溢出。
错误实例 2
实例 2 是实例 1 的变种,Java代码未作修改,但是nativeMethod(int i)的C语言实现稍作修改。在JNI的native method中实现的utility函数中创建Java的String对象。utility函数只建立一个String对象,返回给调用函数,但是utility函数对调用者的使用情况是未知的,每个函数都可能调用它,并且同一函数可能调用它多次。在实例 2 中,nativeMethod在循环中调用count次,utility函数在创建一个String对象后即返回,并且会有一个退栈过程,似乎所创建的Local Reference会在退栈时被删除掉,所以应该不会有很多Local Reference被创建。实际运行结果并非如此。
清单 2. Local Reference引发内存泄漏
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
Java 代码部分参考实例 1,未做任何修改。 JNI 代码,nativeMethod(int i) 的 C 语言实现 #include<stdio.h> #include<jni.h> #include"TestLocalReference.h" jstring CreateStringUTF(JNIEnv * env) { return (*env)->NewStringUTF(env, "0"); } JNIEXPORT void JNICALL Java_TestLocalReference_nativeMethod (JNIEnv * env, jobject obj, jint count) { jint i = 0; for(; i<count; i++) { str = CreateStringUTF(env); } } 运行结果 JVMCI161: FATAL ERROR in native method: Out of memory when expanding local ref table beyond capacity at TestLocalReference.nativeMethod(Native Method) at TestLocalReference.main(TestLocalReference.java:9) |
运行结果证明,实例 2 的结果与实例 1 的完全相同。过多的Local Reference被创建,仍然导致了JNI内部的 JNI Local Reference表内存溢出。实际上,在utility函数CreateStringUTF(JNIEnv * env)
执行完成后的退栈过程中,创建的Local Reference并没有像native code中的局部变量那样被删除,而是继续在Local Reference表中存在,并且有效。Local Reference 和局部变量有着本质的区别。
Local Reference深层解析
Java JNI的文档规范只描述了JNI Local Reference是什么(存在的目的),以及应该怎么使用Local Reference(开放的接口规范)。但是对Java虚拟机中JNI Local Reference的实现并没有约束,不同的Java虚拟机有不同的实现机制。这样的好处是,不依赖于具体的JVM实现,有好的可移植性;并且开发简单,规定了“应该怎么做、怎么用”。但是弊端是初级开发者往往看不到本质,“不知道为什么这样做”。对Local Reference没有深层的理解,就会在编程过程中无意识的犯错。
Local Reference和Local Reference表
理解Local Reference表的存在是理解JNI Local Reference的关键。
JNI Local Reference的生命期是在native method的执行期(从Java程序切换到native code环境时开始创建,或者在native method执行时调用JNI function创建),在 native method执行完毕切换回Java程序时,所有JNI Local Reference被删除,生命期结束(调用JNI function可以提前结束其生命期)。
实际上,每当线程从Java环境切换到native code上下文时(J2N),JVM会分配一块内存,创建一个Local Reference表,这个表用来存放本次native method执行中创建的所有的Local Reference。每当在native code中引用到一个Java对象时,JVM就会在这个表中创建一个Local Reference。比如,实例 1 中我们调用NewStringUTF()在Java Heap中创建一个String对象后,在Local Reference表中就会相应新增一个Local Reference。
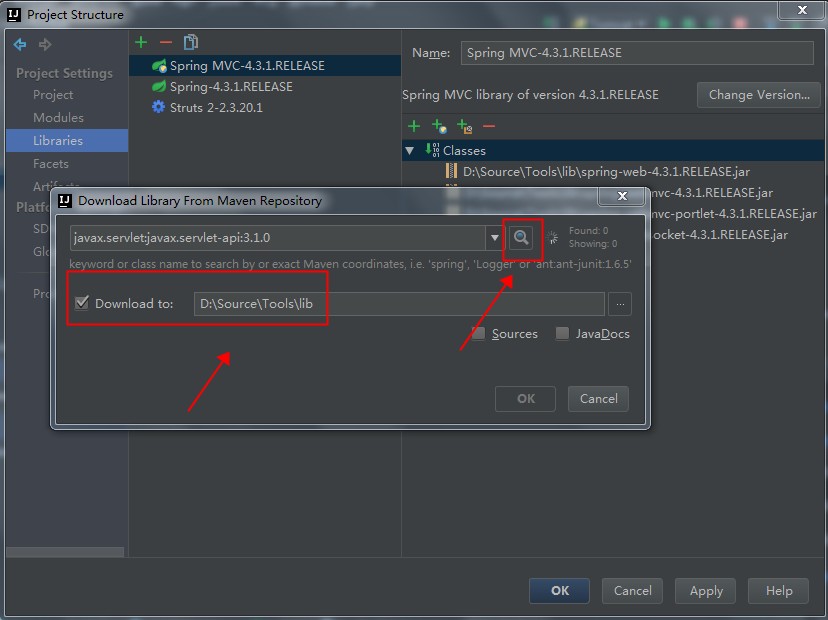
图 1. Local Reference表、Local Reference和Java对象的关系
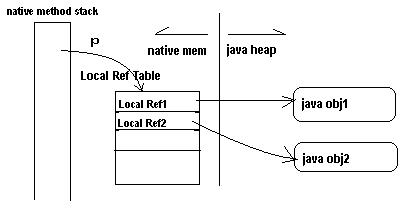
图 1 中:
⑴运行native method的线程的堆栈记录着Local Reference表的内存位置(指针 p)。
⑵ Local Reference表中存放JNI Local Reference,实现Local Reference到Java对象的映射。
⑶ native method代码间接访问Java对象(java obj1,java obj2)。通过指针p定位相应的Local Reference的位置,然后通过相应的Local Reference映射到Java对象。
⑷ 当native method引用一个Java对象时,会在Local Reference表中创建一个新Local Reference。在Local Reference结构中写入内容,实现Local Reference到Java对象的映射。
⑸native method调用DeleteLocalRef()释放某个JNI Local Reference时,首先通过指针p定位相应的Local Reference在Local Ref表中的位置,然后从Local Ref表中删除该Local Reference,也就取消了对相应Java对象的引用(Ref count减1)。
⑹当越来越多的Local Reference被创建,这些Local Reference会在Local Ref表中占据越来越多内存。当Local Reference太多以至于Local Ref表的空间被用光,JVM会抛出异常,从而导致JVM的崩溃。
Local Ref不是native code的局部变量
很多人会误将JNI中的Local Reference理解为Native Code的局部变量。这是错误的。
Native Code的局部变量和Local Reference是完全不同的,区别可以总结为:
⑴局部变量存储在线程堆栈中,而Local Reference存储在Local Ref表中。
⑵局部变量在函数退栈后被删除,而Local Reference在调用DeleteLocalRef()后才会从Local Ref表中删除,并且失效,或者在整个Native Method执行结束后被删除。
⑶ 可以在代码中直接访问局部变量,而Local Reference的内容无法在代码中直接访问,必须通过JNI function间接访问。JNI function实现了对Local Reference的间接访问,JNI function的内部实现依赖于具体JVM。
代码清单 1 中 str = (*env)->NewStringUTF(env, "0");
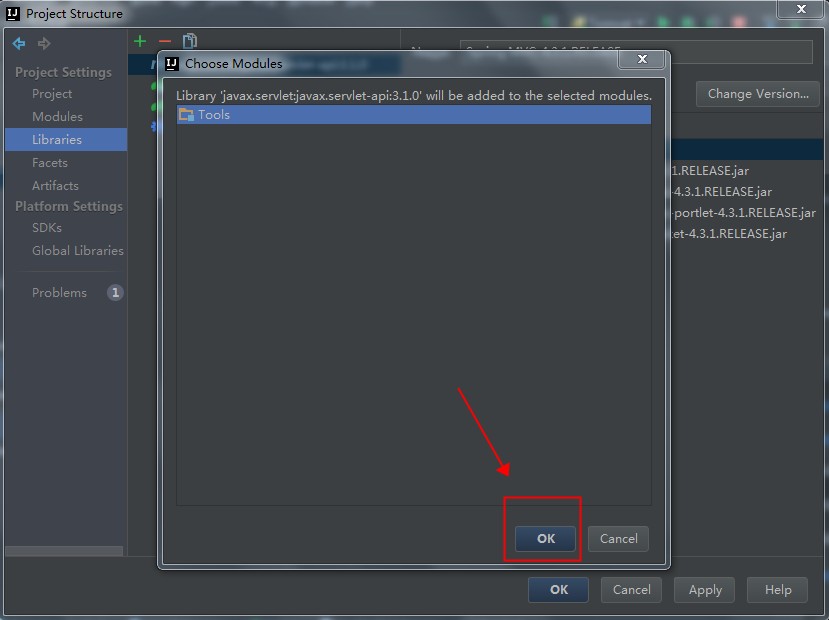
str是jstring类型的局部变量。Local Ref表中会新创建一个Local Reference,引用到NewStringUTF(env, "0")在Java Heap中新建的String对象。如图 2 所示:
图 2. str 间接引用 string 对象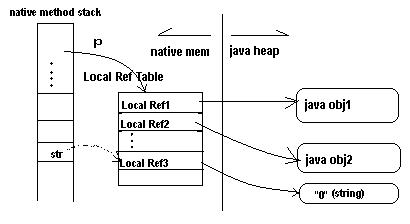
图 2 中,str 是局部变量,在 native method 堆栈中。Local Ref3 是新创建的 Local Reference,在 Local Ref 表中,引用新创建的 String 对象。JNI 通过 str 和指针 p 间接定位 Local Ref3,但 p 和 Local Ref3 对 JNI 程序员不可见。
Local Reference导致内存泄漏
在以上论述基础上,我们通过分析错误实例 1 和实例 2,来分析 Local Reference 可能导致的内存泄漏,加深对 Local Reference 的深层理解。
分析错误实例 1:
局部变量str在每次循环中都被重新赋值,间接指向最新创建的Local Reference,前面创建的Local Reference 一直保留在 Local Ref 表中。
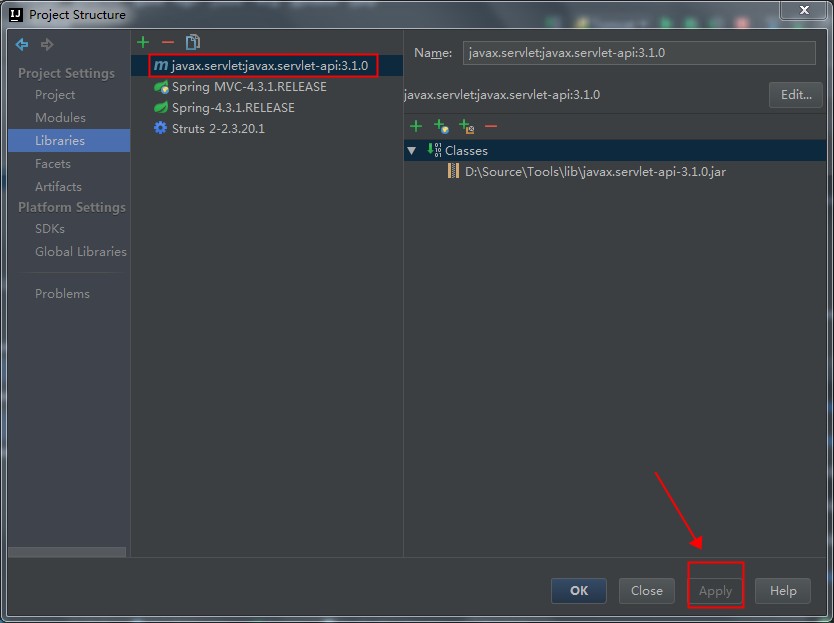
在实例 1 执行完第i次循环后,内存布局如图 3:
图 3. 执行i次循环后的内存布局
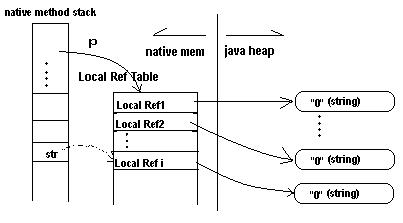
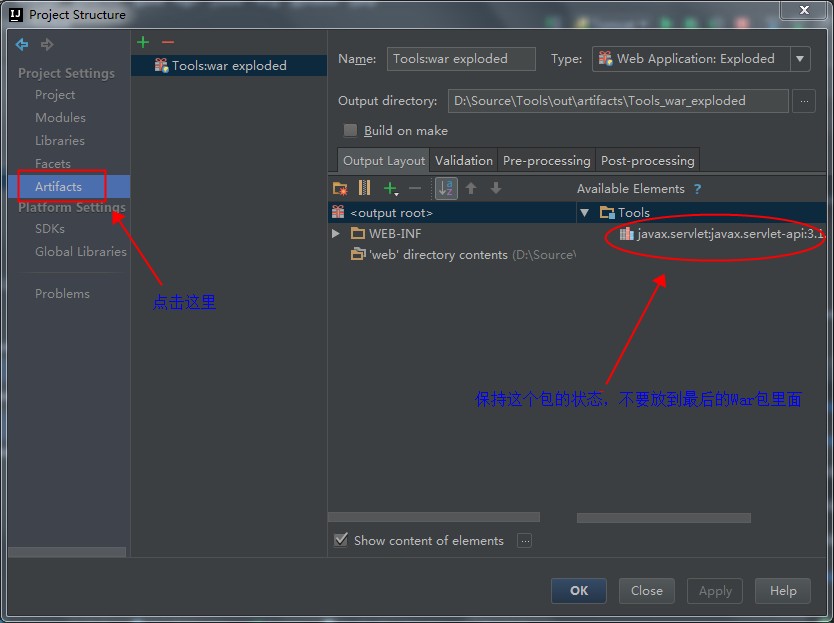
继续执行完第i+1次循环后,内存布局发生变化,如图 4:
图 4. 执行i+1次循环后的内存布局
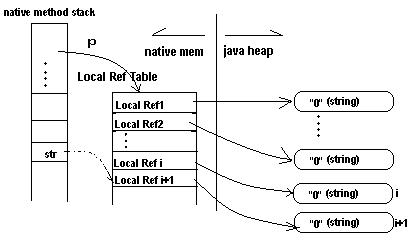
图 4 中,局部变量 str 被赋新值,间接指向了Local Ref i+1。在native method运行过程中,我们已经无法释放Local Ref i占用的内存,以及Local Ref i所引用的第i个 string对象所占据的Java Heap内存。所以,native memory中Local Ref i被泄漏,Java Heap中创建的第 i个string对象被泄漏了。
也就是说在循环中,前面创建的所有i个Local Reference都泄漏了native memory的内存,创建的所有 i 个string对象都泄漏了Java Heap的内存。
直到native memory执行完毕,返回到Java程序时(N2J),这些泄漏的内存才会被释放,但是 Local Reference 表所分配到的内存往往很小,在很多情况下N2J之前可能已经引发严重内存泄漏,导致Local Reference表的内存耗尽,使JVM崩溃,例如错误实例 1。
分析错误实例 2:
实例 2 与实例 1 相似,虽然每次循环中调用工具函数CreateStringUTF(env)来创建对象,但是在CreateStringUTF(env)返回退栈过程中,只是局部变量被删除,而每次调用创建的Local Reference仍然存在Local Ref表中,并且有效引用到每个新创建的string对象。str局部变量在每次循环中被赋新值。
这样的内存泄漏是潜在的,但是这样的错误 在JNI程序员编程过程中却经常出现。通常情况,在触发out of memory之前,native method已经执行完毕,切换回 Java 环境,所有 Local Reference 被删除,问题也就没有显露出来。但是某些情况下就会引发out of memory,导致实例 1 和实例 2 中的JVM崩溃。
控制Local Reference生命期
因此,在JNI编程时,正确控制JNILocal Reference的生命期。如果需要创建过多的Local Reference,那么在对被引用的Java对象操作结束后,需要调用JNI function(如 DeleteLocalRef()),及时将JNILocal Reference从Local Ref表中删除,以避免潜在的内存泄漏。
总结
本文阐述了JNI编程可能引发的内存泄漏,JNI编程既可能引发Java Heap的内存泄漏,也可能引发native memory的内存泄漏,严重的情况可能使JVM运行异常终止。JNI软件开发人员在编程中,应当考虑以下几点,避免内存泄漏:
native code本身的内存管理机制依然要遵循。- 使用
Global reference时,当native code不再需要访问Global reference时,应当调用JNI函数DeleteGlobalRef()删除Global reference和它引用的Java对象。Global reference管理不当会导致Java Heap的内存泄漏。
- 透彻理解
Local reference,区分Local reference和native code的局部变量,避免混淆两者所引起的native memory的内存泄漏。
- 使用
Local reference时,如果Local reference引用了大的Java对象,当不再需要访问Local reference时,应当调用JNI函数DeleteLocalRef()删除Local reference,从而也断开对Java对象的引用。这样可以避免Java Heap的out of memory。
- 使用
Local reference时,如果在native method执行期间会创建大量的Local reference,当不再需要访问Local reference时,应当调用JNI函数DeleteLocalRef()删除Local reference。Local reference表空间有限,这样可以避免Local reference表的内存溢出,避免native memory的out of memory。
- 严格遵循
JavaJNI规范书中的使用规则。
参考链接
在 JNI 编程中避免内存泄漏