本文介绍了 Intel QAT 技术方案,通过 Multi-Buffer 技术和 QAT 硬件加速卡的两种方式实现对 TLS 的加速
一、背景
当前 TLS 已经成为了互联网安全的主要传输协议,TLS 带来更高的安全性的同时,也带来了更多的性能开销。特别是在建连握手阶段,TLS 的 CPU 开销,相对于 TCP 要大很多。
业界在优化 TLS 性能上已经做了很多软件和协议层面的优化,包括:Session 复用、OCSP Stapling、TLS1.3等。然而在摩尔定律"失效"的今日,软件层面的优化很难满足日益增长的流量,使用专用的硬件技术卸载 CPU 计算成为目前通用的解决方案。本文将介绍 Intel 在 TLS 加速领域提供的 QAT 技术方案。
二、Intel QuickAssist Technology(QAT)技术方案
Intel 提供了 TLS 异步加速的完整解决方案: Intel QuickAssist Technology(QAT),简称 Intel QAT 技术。
如下图所示,QAT 支持加速的密码算法覆盖了 TLS 的整个流程,包括:握手阶段的签名、秘钥交换算法,数据传输的 AES 加解密算法等。
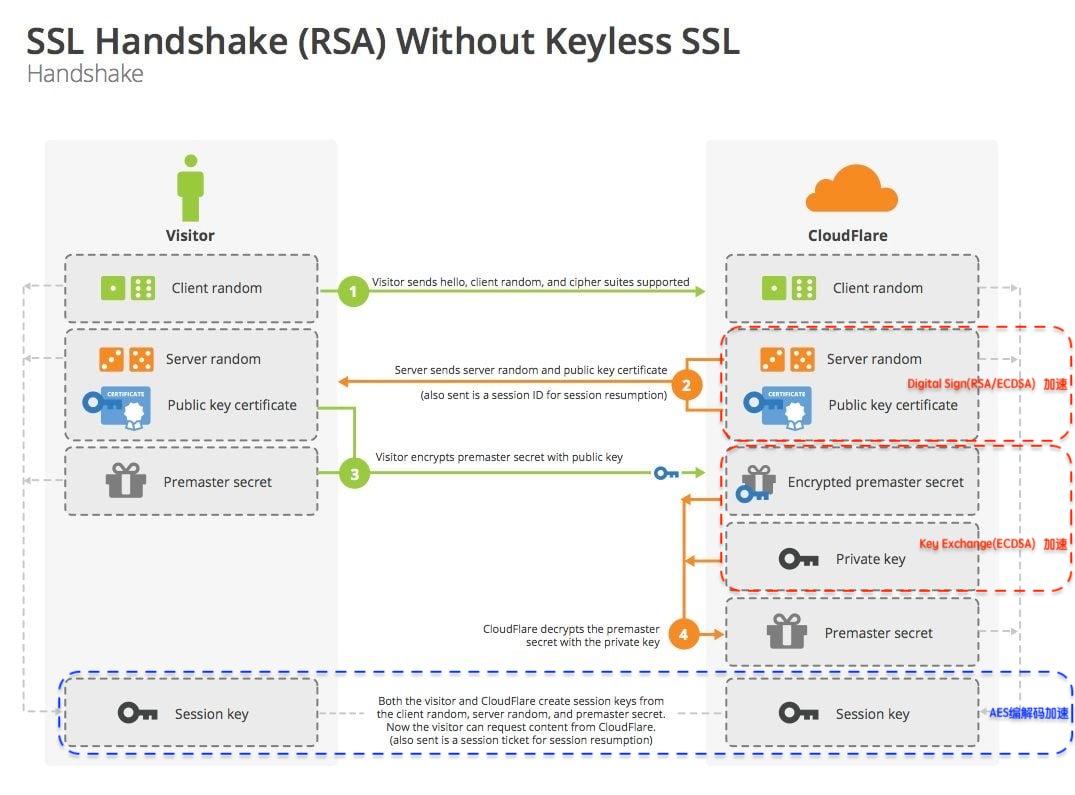
QAT 提供了对称与非对称两类密码算法的支持,主要包括:
- 非对称加密算法:RSA, ECDSA, ECDHE
- 对称加密算法:AES-GCM(128,192,256)
注:QAT 加速的优势主要体现在非对称加密上,从官方的整体性能数据看,非对称算法性能提升 1.6~2 倍,对称算法性能提升 10%~15%
2.1 QAT Engine 软件栈
QAT Engine 是 QAT 技术方案的核心模块,主要的作用是作为应用程序和硬件之间的中间层,负责 “加解密操作的输入输出数据” 在用户应用程序与硬件卡之间进行传递,主要操作就是IO的读写。
QAT Engine 是以 OpenSSL 第三方插件的方式提供给用户,这个意味用户可以使用 OpenSSL 标准的 API,就可以实现对 TLS 的加速,只需要对原有代码做 OpenSSL 异步改造,就可以享受 QAT 技术带来的 TLS 性能加速,业务侵入性较小。
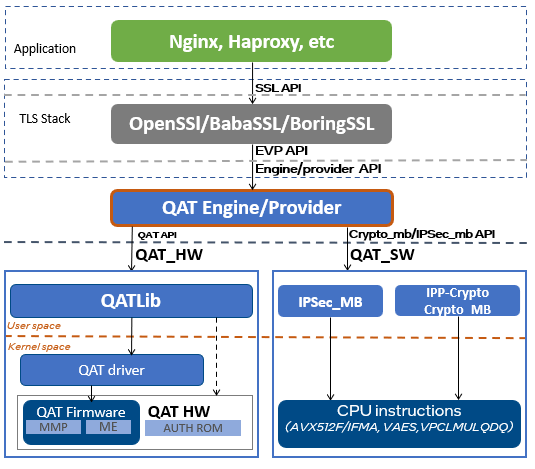
如上图所示,QAT Engine 支持两种加速方式:
- 软件加速(qat_sw):使用 Multi-Buffer (SIMD)技术,对密码算法进行并行处理优化。
- 硬件加速(qat_hw):使用 QAT 硬件加速卡,将密码算法计算从 CPU OffLoad 到硬件加速卡。
下面将介绍软件和硬件两种加速路径的实现方式。
三、软件加速:采用 Intel Multi-Buffer 技术
Intel 从 Whitely 平台开始加入了新的指令集,结合 Intel Multi-Buffer 技术,实现对密码算法的 SIMD 优化方案。
3.1 Intel Multi-Buffer 技术
Intel Multi-buffer 基本原理就是使用 CPU 的 SIMD 机制,通过 AVX-512 指令集并行处理数据,来提升RSA/ECDSA算法性能。
- SIMD (Single Instruction Multiple Data) 即单指令流多数据流,是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。简单来说就是一个指令能够同时处理多个数据。
- Multi-Buffer 技术基于 SIMD AVX-512 指令集,通过队列和批量提交策略,结合 OpenSSL 的异步能力,每次可以最多并行处理8个密码算法操作。
Intel 的 Multi-Buffer 方案,实际上是对应 Intel 两个开源工程( Multi Buffer 技术实现的通用密码算法底层lib库),集成在 QAT Engine 里,从而实现软件加速。

1、IP SEC lib
- 提供了 Multi-Buffer 技术优化的对称加解密算法,如:AES-GCM
- 开源项目:https://github.com/intel/intel-ipsec-mb
2、IPP CRYPTO lib
- 提供了 Multi-Buffer 技术优化的 RSA/EDCSA/EDCHE 算法接口,基于 Intel® Advanced Vector Extensions 512 (Intel® AVX-512) integer fused multiply-add (IFMA) 指令实现SIMD优化。
- 开源项目:https://github.com/intel/ippcrypto/tree/develop/sources/ippcp/crypto_mb
简而言之,QAT 的软件加速的本质就是通过 AVX-512 指令集进行并行处理优化,针对并发场景性能有显著提升(下文有针对 Multi-Buffer 优化场景的性能测试)。
四、 硬件加速:采用QAT硬件加速卡卸载
除了通过 Multi-Buffer 技术进行软件加速外,QAT Engine 还支持 QAT 硬件加速卡,通过将密码算法的计算卸载(OffLoad)到硬件加速卡,实现性能加速。
硬件加速核心是将 TLS 中的非对称加解密操作剥离出来,放到硬件加速卡里计算,即解放了 CPU,同时专用的硬件加速卡也提供了更高的加解密性能,这是典型的硬件 OffLoad 技术方案。
下图为典型的 Nginx+ Intel QAT Software Stack + QAT 硬件加速卡的典型应用场景:
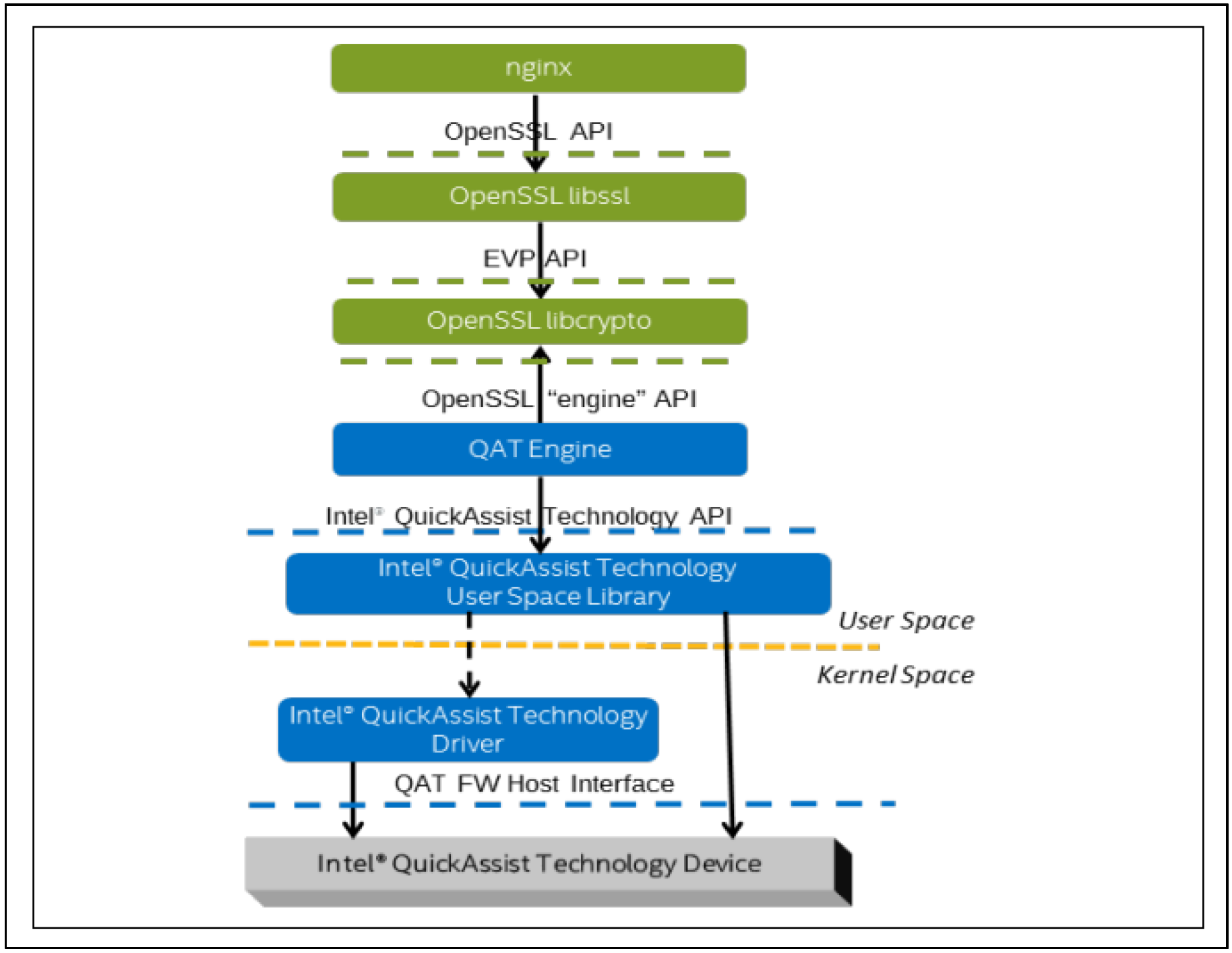
这个典型应用场景包括四个部分:
- Nginx (Async Mode): Intel 基于官方 Nginx(Version 1.18)提供了 Patch,支持 Nginx 工作在 OpenSSL 的异步模式。Patch开源在:https://github.com/intel/asynch_mode_nginx
- OpenSSL(支持Async Mode): OpenSSL-1.1.1 新增了 async mode 特性,应用层软件可以通过标准的 OpenSSL 接口,实现异步调用,提升性能。
- QAT Engine: OpenSSL Engine 插件。向下和 QAT API 交互,将处理请求提交给硬件。详见项目开源地址: https://github.com/intel/QAT_Engine
- QAT Driver:QAT 加速卡的驱动程序。分为用户态和内核态两个部分。用户态的 LIB 库提供 QAT API,内核态的driver则直接和 QAT 硬件加速卡打交道。
Intel QAT 依赖了 OpenSSL 的两个特性 OpenSSL Async Mode 和 OpenSSL Engine:
- OpenSSL Async Mode 能够在 async_job 执行过程中,在等待加速卡结果的时候,将 CPU 让出去;如果没有开启 async 模式,调用 OpenSSL 函数会阻塞,CPU 会阻塞等待。
- OpenSSL Engine 则是提供了自定义注册加解密的方法,可以不使用 OpenSSL 自带的加解密库,指定调用第三方的加解密库。
基于两个特性,应用程序的加解密操作只需要保持使用原来相同 OpenSSL API,只需要做异步模式的兼容。另外,可以在调用 OpenSSL 的 API 时,指定到 Engine QAT上就行,不需要做任何额外的修改,就可以使用 QAT 卡进行加解密加速。
4.1 OpenSSL 的Async Mode特性
通过上面的介绍,我们可以看到 QAT 卡的本质是让一部分原本由 CPU 进行的计算转移到 QAT 卡上进行,因此提高 QAT 的利用率,降低 CPU 的切换开销和等待时间是性能最大化的核心工作。
OpenSSL 未启用异步ASYNC模式时,OpenSSL 调用是同步阻塞的,直到QAT_Engine返回结果。如下图的同步模式,在并发处理执行流的场景,大量CPU处于空闲等待的状态(图中虚线表示CPU处于空闲状态),无法有效地利用CPU。
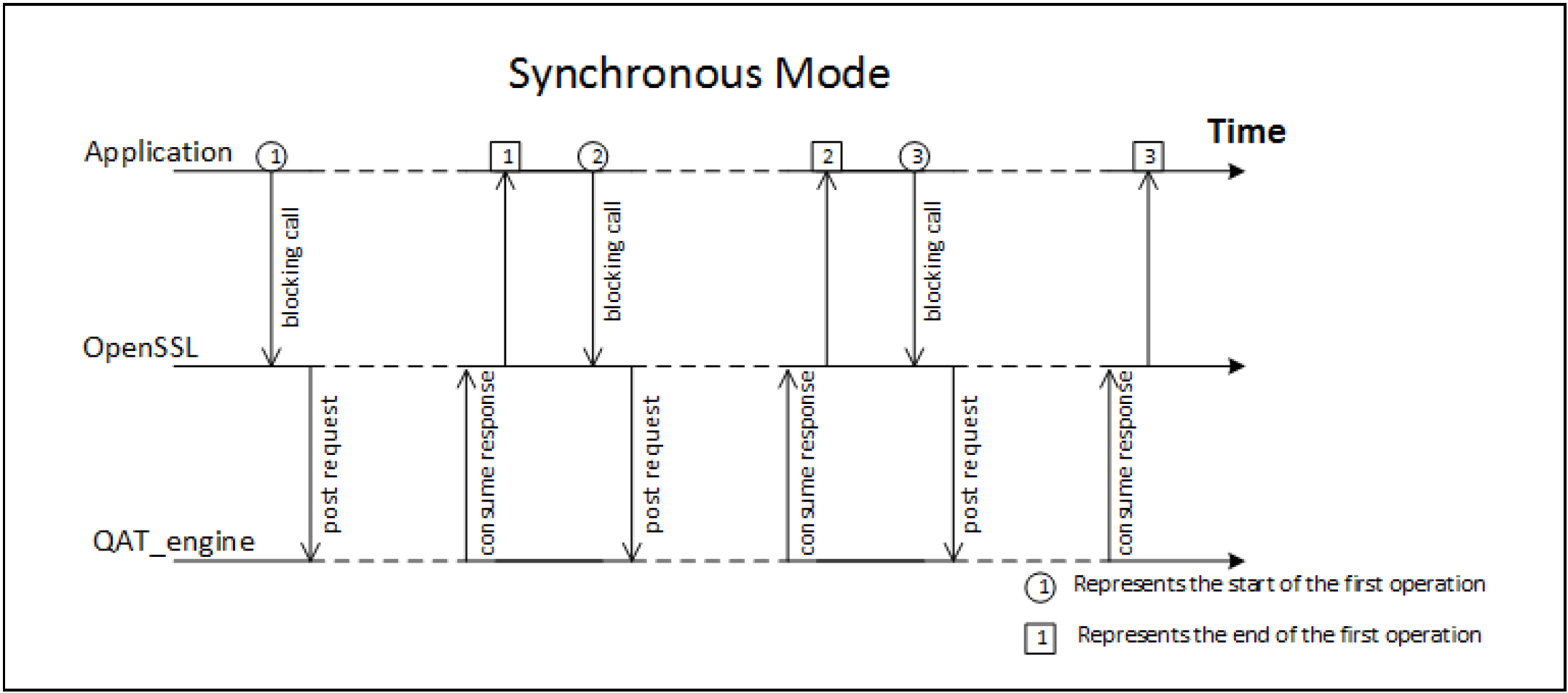
OpenSSL 开启异步 ASYNC 模式后,OpenSSL 调用是非阻塞的。如下图的异步模式,OpenSSL 的调用不需要等待QAT_engine的处理完成,可以有效地利用 CPU,提高 QAT 的利用率,提升并发处理性能。
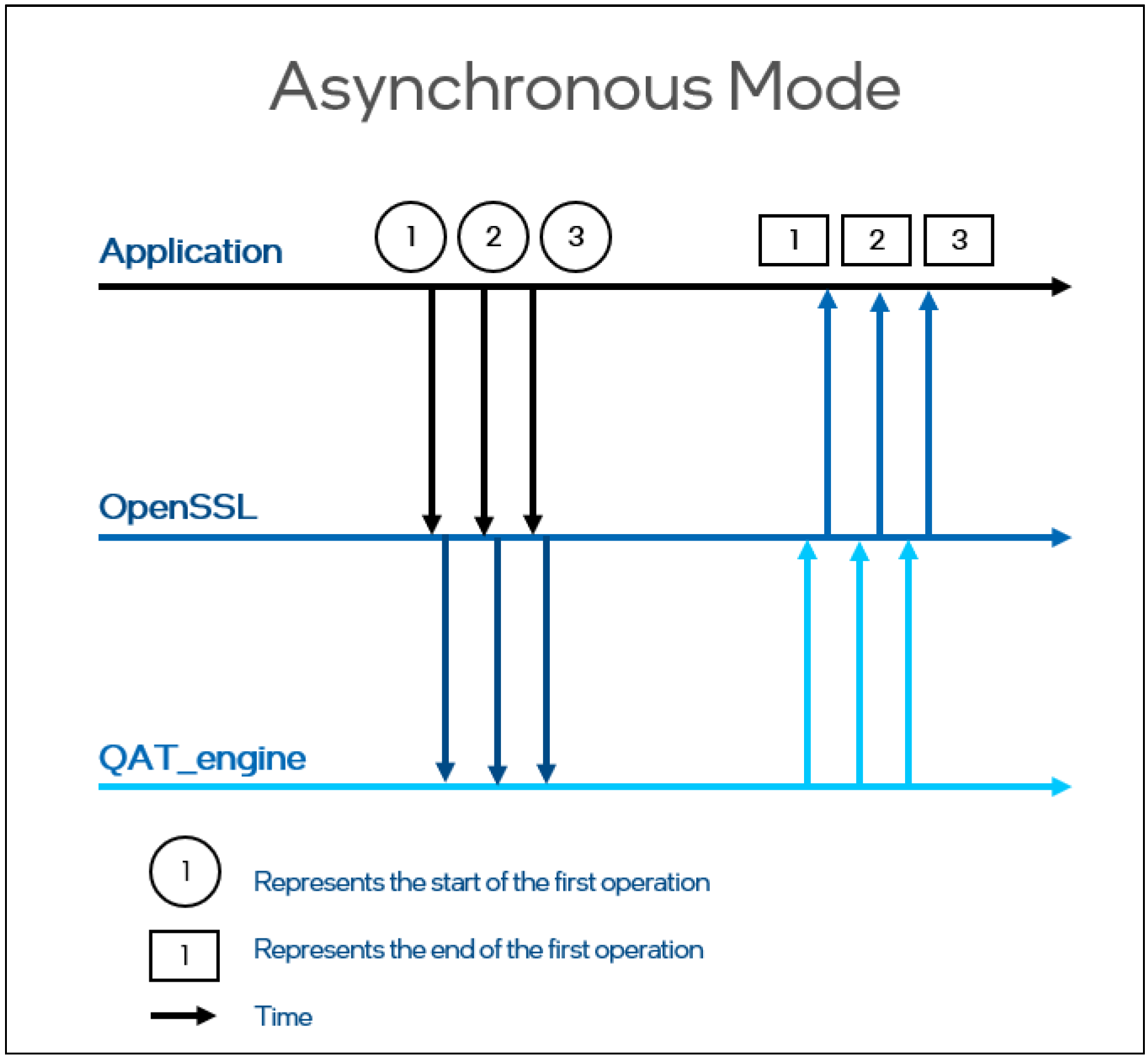
通过 OpenSSL 的同步和异步模式的对比,可以看到 OpenSSL-1.1.1 新增的异步 Async 特性,支持了异步非阻塞调用,提高了 QAT 的利用率,可以显著提升加解密性能。
4.2 QAT Engine ASYNC运行流程
接下来还有一个问题,CPU 如何知道 QAT 卡完成了计算呢?
Async模块为了达到并行的目的,在单线程中实现了协程(async job)。加解密操作抽象为job,多个job同时运行,使用协程进行调度。
在async job执行的过程中,当计算操作提交给QAT卡后,CPU 可以把当前任务暂停,切换上下文(保存/恢复栈,寄存器等)返回给用户态。
用户态需要主动去poll这个async job的状态,是否是ASYNC_FINISHED状态。如果是,说明之前的任务已经完成,则可以继续后面的操作(取回加密/解密结果)。
注:QAT Engine 通过轮询来获取QAT卡的计算状态,基本原理是启动一个线程,不停的调用qatdriver的polling api,轮询获取qat的计算状态,得到相应结果后,写入eventfd,唤醒async job。
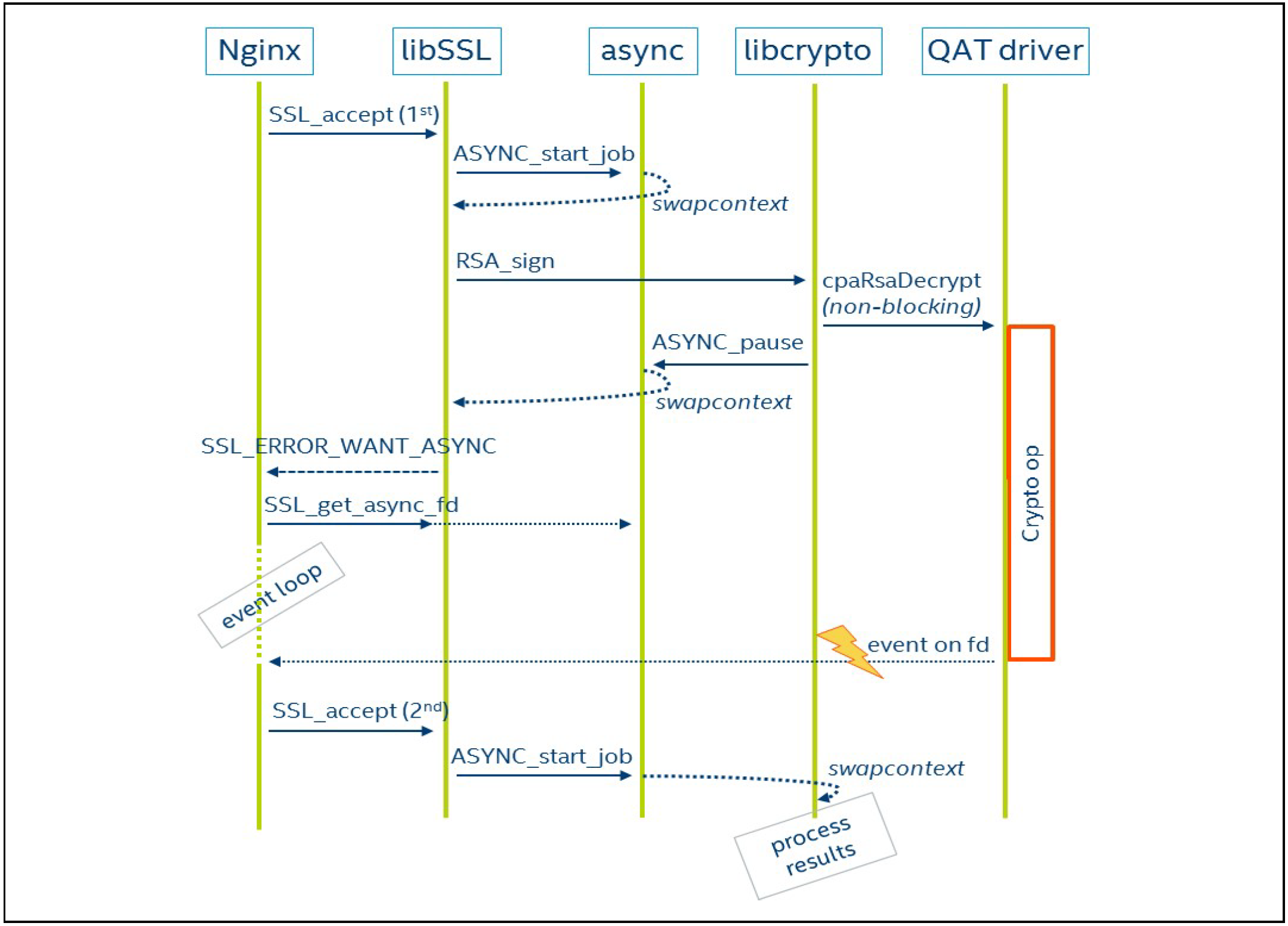
如上图所示,QAT Engine Async的基本流程为:
- 主 job 调用 SSL_accept,等待 TLS 客户端发起 TLS handshake。
- SSL 内部组织了一个状态机,将握手,读写等操作抽象为两个job,ssl_io_intern(读写), ssl_do_handshake_intern(握手), 统一通过api ASYNC_start_job()进行job调度。这里启动了一个握手的job协程。
- 握手job执行 RSA_sign 签名操作时,将sign算法卸载到硬件上计算。调用 ASYNC_pause_job() 切回主job, 并将job状态设置为 ASYNC_PAUSE ,这个时候 CPU 会交还给主 job 进行其它计算工作,同时 QAT 并行的进行自己的计算。
- 主job通过SSL_waiting_for_async() 接口获得的一个eventfd,并epoll这个eventfd。当 QAT 卡计算完成,会执行回调写入eventfd,通知主job计算已完成。
- 主job切换回握手job,握手job的完成剩余流程后,再调用ASYNC_pause_job()切换主job,并将job状态设置为ASYNC_FINISH,结束协程完成握手动作。
五、QAT 性能评测
通过上面的介绍,我们了解了 QAT 技术方案的基本原理,下面我们看下 QAT 的实际加速效果。
QAT Multi-Buffer 加速方案,依赖的 OpenSSL、QAT Engine、ipp-crypto、 Intel-ipsec-mb 软件栈都是开源项目,我们可以方便的使用 OpenSSL Speed 原生加解密算法对 Multi-Buffer 方案进行性能评估。
硬件环境
- Intel(R) Xeon(R) Platinum 8369B CPU @ 2.70GHz
- CPU(s): 8
软件环境
- Linux Kernel: 4.19.91-24.1.al7.x86_64
- OpenSSL 1.1.1g
- gcc (GCC) 8.3.0
- cmake version 3.15.5
- NASM version 2.15.05
- GNU Binutils 2.32
- 安装 QAT Engine
- 安装 ipp-crypto、 Intel-ipsec-mb 开源lib库
测试数据
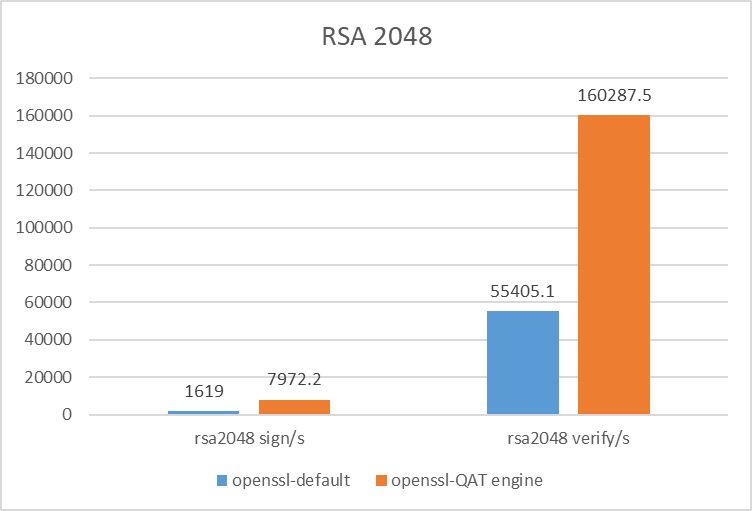
- numactl -C 0 ./openssl speed rsa2048
- numactl -C 0 ./openssl speed -engine qatengine -async_jobs 8 rsa2048
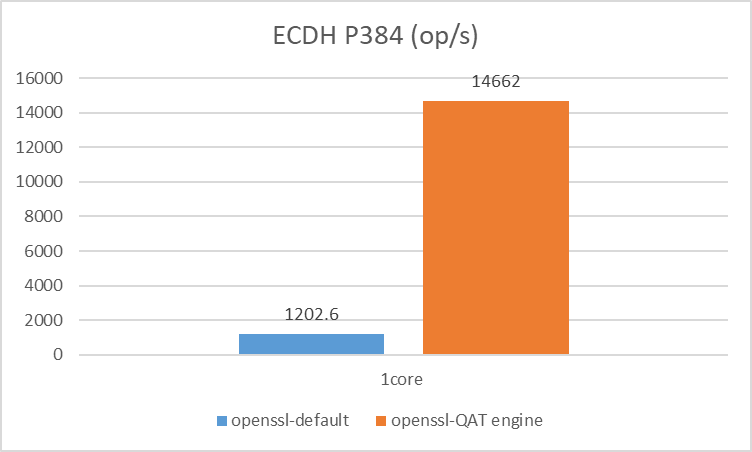
- numactl -C 0 ./openssl speed ecdhp384
- numactl -C 0 ./openssl speed -engine qatengine -async_jobs 8 ecdhp384
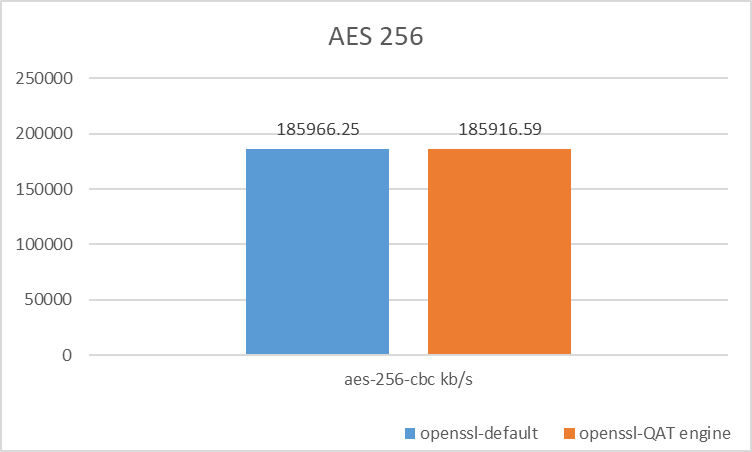
- numactl -C 0 ./openssl speed aes-256-cbc
- numactl -C 0 ./openssl speed -engine qatengine -async_jobs 8 aes-256-cbc
TLS 握手阶段的签名和秘钥交换算法
- RSA 2048 Sign/Verify 提升 4.9/2.9倍
- ECDH Key Exchange 提升 12倍
对称加解密算法
- AES-256-CBC 性能持平
根据性能测试结果,QAT 的加速优势在于 TLS 握手阶段的签名和秘钥交换算法,适合频繁进行 TLS 建连的应用场景,比如:Nginx 网关、长连接网关等。
六、总结
本文介绍了 Intel QAT 技术方案,并讨论了方案提供的 Multi-Buffer 软件加速以及 QAT 硬件加速两种方式。同时,通过性能评估测试,我们可以看到 QAT 技术对 TLS 握手阶段的加解密算法有显著的性能提升。
最后,我们讨论一下 Intel QAT 技术的优缺点和应用场景:
6.1 优点和缺点
主要的优点
- 高性能:可以显著提高计算密集型任务的性能,减少 CPU 的负载,提高系统吞吐量和响应速度。
- 低功耗:可以将计算密集型任务卸载到专用硬件上,降低系统功耗,提高能效比。
主要的缺点
- 成本较高:需要额外的硬件支持,增加了系统的成本。
- 应用范围受限:主要适用于计算密集型任务,对于其他类型的任务可能没有显著的性能提升。
- 不支持所有处理器:只支持 Intel 特定系列的处理器,需要特定的硬件和软件支持。
- 改造成本高:需要对应用程序进行 QAT 异步化改造,需要一定的学习成本和技术支持。
6.2 应用场景
除了加解密算法之外,Intel QAT 还支持压缩和解压缩、随机数生成、数字签名、视频编解码等算法。Intel QAT 主要可以用于以下场景:
- 接入网关:比如 Nginx 网关、长连接网关。QAT 可以加速 TLS 协议处理,提升网关的性能
- 虚拟私人网络(VPN):QAT 可以加速 VPN 流量的加密和解密过程,提高吞吐量,减少延迟
- 存储加速:QAT 可以加速数据压缩和解压缩,减少需要传输和存储的数据量
- 视频编解码:QAT 可以加速视频编解码算法,提高视频处理的效率和质量
总的来说,Intel QAT 可以将计算密集型任务从 CPU 中分离出来,显著提高系统的性能和能效比,可以广泛应用于计算密集型任务的加速,包括网络安全、数据处理、云计算、存储加速、视频处理等多个领域。
参考资料
- Github:intel/QAT_Engine
- Intel® QuickAssist Technology (Intel® QAT)
- Intel® QuickAssist Technology & OpenSSL-1.1.0: Performance
- TLS
- Intel® Processor Architecture: SIMD InstructionsSIMD Instructions
- [openssl] openssl async模块框架分析
- TLS 加速技术:Intel QuickAssist Technology(QAT)解决方案
- Keyless SSL: The Nitty Gritty Technical Details
- TLS 加速技术:Intel QuickAssist Technology(QAT)解决方案


{kind=link}
{kind=link}