前言
看了咸鱼这篇《万万没想到——flutter这样外接纹理》的文章,我们了解到 Flutter 提供一种机制,可以将 Native 的纹理共享给 Flutter 来进行渲染。但是,由于 Flutter 获取 Native 纹理的数据类型是 CVPixelBuffer,导致 Native 纹理需要经过 GPU->CPU->GPU 的转换过程消耗额外性能,这对于需要实时渲染的音视频类需求,是不可接受的。
闲鱼这边的解决方案是修改了 Flutter Engine 的代码,将 Flutter 的 GL 环境和 native 的 GL 环境通过 ShareGroup 来联通,避免2个环境的纹理传递还要去 CPU 内存绕一圈。此方案能够解决内存拷贝的性能问题,但暴露 Flutter 的 GL 环境,毕竟是一个存在风险的操作,给以后的 Flutter 渲染问题定位也增加了复杂度。所以,有没有一个完美、简便的方案呢?答案就是利用 CVPixelBuffer 的共享内存机制。
Flutter外接纹理的原理
先回顾下前置知识,看看官方提供的外接纹理机制究竟是怎样运行的。
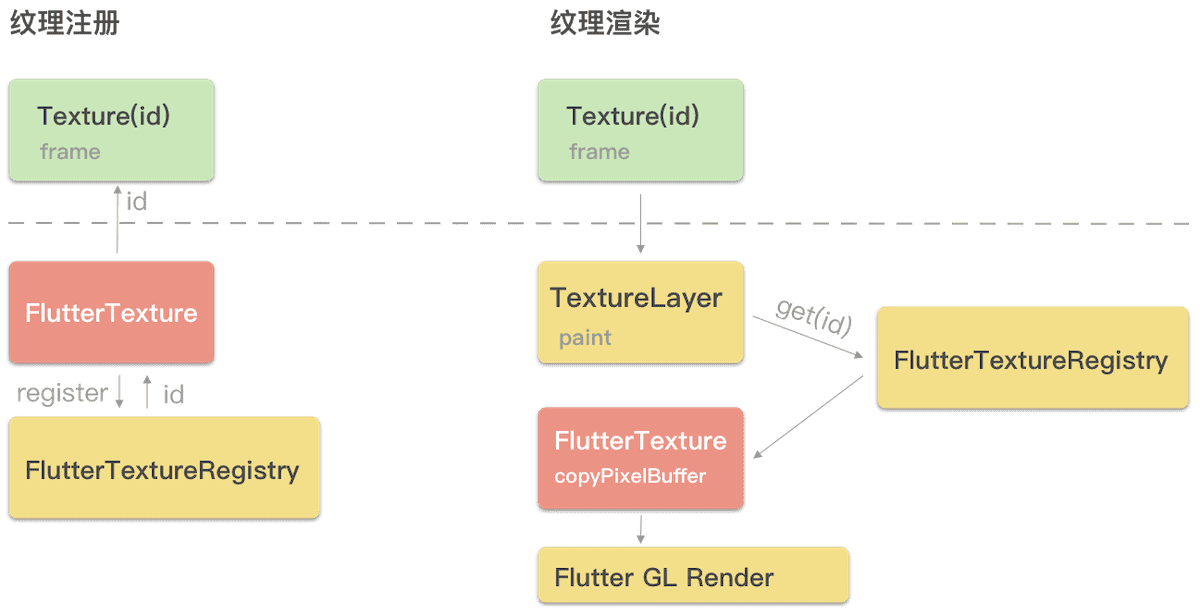
图中红色块,是我们自己要编写的 Native 代码,黄色是 Flutter Engine 的内部代码逻辑。整体流程分为注册纹理,和整体的纹理渲染逻辑。
注册纹理
- 创建一个对象,实现FlutterTexture协议,该对象用来管理具体的纹理数据
- 通过FlutterTextureRegistry来注册第一步的FlutterTexture对象,获取一个flutter纹理id
- 将该id通过channel机制传递给dart侧,dart侧就能够通过Texture这个widget来使用纹理了,参数就是id
纹理渲染
- dart侧声明一个Texture widget,表明该widget实际渲染的是native提供的纹理
- engine侧拿到layerTree,layerTree的TextureLayer节点负责外接纹理的渲染
- 首先通过dart侧传递的id,找到先注册的FlutterTexture,该flutterTexture是我们自己用native代码实现的,其核心是实现了copyPixelBuffer方法
- flutter engine调用copyPixelBuffer拿到具体的纹理数据,然后交由底层进行gpu渲染
CVPixelBuffer格式分析
一切问题的根源就在这里了:CVPixelBuffer。从上面flutter外接纹理的渲染流程来看,native纹理到flutter纹理的数据交互,是通过 copyPixelBuffer 传递的,其参数就是 CVPixelBuffer。而前面咸鱼文章里面说的性能问题,就来自于纹理与 CVPixelBuffer 之间的转换。
那么,如果 CVPixelBuffer 能够和OpenGL的纹理同享同一份内存拷贝,GPU -> CPU -> GPU的性能瓶颈,是否就能够迎刃而解了呢?其实我们看一下flutter engine里面利用CVPixelBuffer来创建纹理的方法,就能够得到答案:
Flutter Engine是使用 CVOpenGLESTextureCacheCreateTextureFromImage 这个接口来从 CVPixelBuffer 对象创建OpenGL纹理的,那么这个接口实际上做了什么呢?我们来看一下官方文档
This function either creates a new or returns a cached CVOpenGLESTextureRef texture object mapped to the CVImageBufferRef and associated parameters. This operation creates a live binding between the image buffer and the underlying texture object. The EAGLContext associated with the cache may be modified to create, delete, or bind textures. When used as a source texture or GL_COLOR_ATTACHMENT, the image buffer must be unlocked before rendering. The source or render buffer texture should not be re-used until the rendering has completed. This can be guaranteed by calling glFlush().
从文档里面,我们了解到几个关键点:
- 返回的纹理对象,是直接映射到了CVPixelBufferRef对象的内存的
- 这块buffer内存,其实是可以同时被CPU和GPU访问的,我们只需要遵循如下的规则:
- GPU访问的时候,该 CVPixelBuffer ,不能够处于lock状态。
使用过pixelbuffer的同学应该都知道,通常CPU操作pixelbuffer对象的时候,要先进行lock操作,操作完毕再unlock。所以这里也容易理解,GPU使用纹理的时候,其必然不能够同时被CPU操作。 - CPU访问的时候,要保证GPU已经渲染完成,通常是指在 glFlush() 调用之后。
这里也容易理解,CPU要读写这个buffer的时候,要保证关联的纹理不能正在被OpenGL渲染。
- GPU访问的时候,该 CVPixelBuffer ,不能够处于lock状态。
我们用instrument的allocation来验证一下:
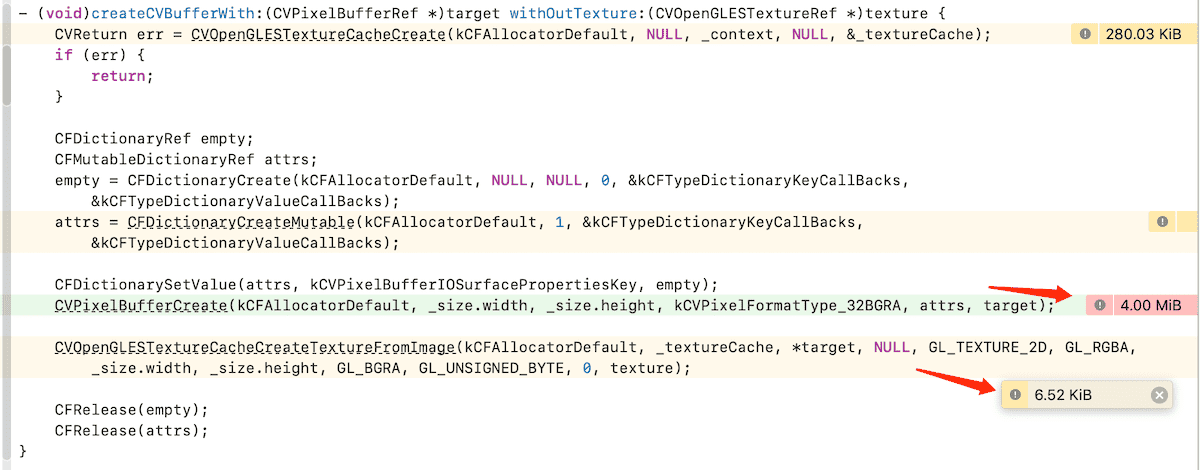
instrument的结果,也能够印证文档中的结论。 只有在创建pixelBuffer的时候,才分配了内存,而映射到纹理的时候,并没有新的内存分配。
这里也能印证我们的结论,创建pixelBuffer的时候,才分配了内存,映射到纹理的时候,并没有新的内存分配。
共享内存方案
既然了解到CVPixelBuffer对象,实际上是可以桥接一个OpenGL的纹理的,那我们的整体解决方案就水到渠成了,可以看看下面这个图
![]()
关键点在于,首先需要创建pixelBuffer对象,并分配内存。然后在native gl环境和flutter gl环境里面分别映射一个纹理对象。这样,在2个独立的gl环境里面,我们都有各自的纹理对象,但实际上其内存都被映射到同一个CVPixelBuffer上。在实际的每一帧渲染流程里面,native环境做渲染到纹理,而flutter环境里面则是从纹理读取数据。
Demo演示
这里我写了个小demo来验证下实际效果,demo的主要逻辑是以60FPS的帧率,渲染一个旋转的三角形到一个pixelBuffer映射的纹理上。然后每帧绘制完成之后,通知 Flutter 侧来读取这个pixelBuffer对象去做渲染。

核心代码展示如下:
关键代码都添加了注释,这里就不分析了
我们从上面的gif图上可以看到整个渲染过程是十分流畅的,最后看displayLink的帧率也能够达到60FPS。该demo是可以套用到其他的需要CPU与GPU共享内存的场景的。
完整的demo代码在这里flutter_texture